ma ha davvero 2.41 miliardi di transistors???
(… )
2.41B di kaveri vs 1.30B di trinity/richland, sarà anche merito dei 28nm vs 32nm, ma il +85% è un enormità sulla stessa superficie e con caratteristiche simili o comunque di una diretta evoluzione (2m/4c , igpu di poco superiore da 512sp , IMC in effetti doppio e soprattutto TDP uguale 95w vs 100w)... mah... haswell i7-4770k quanti ne ha?
già, un bel boost in avanti
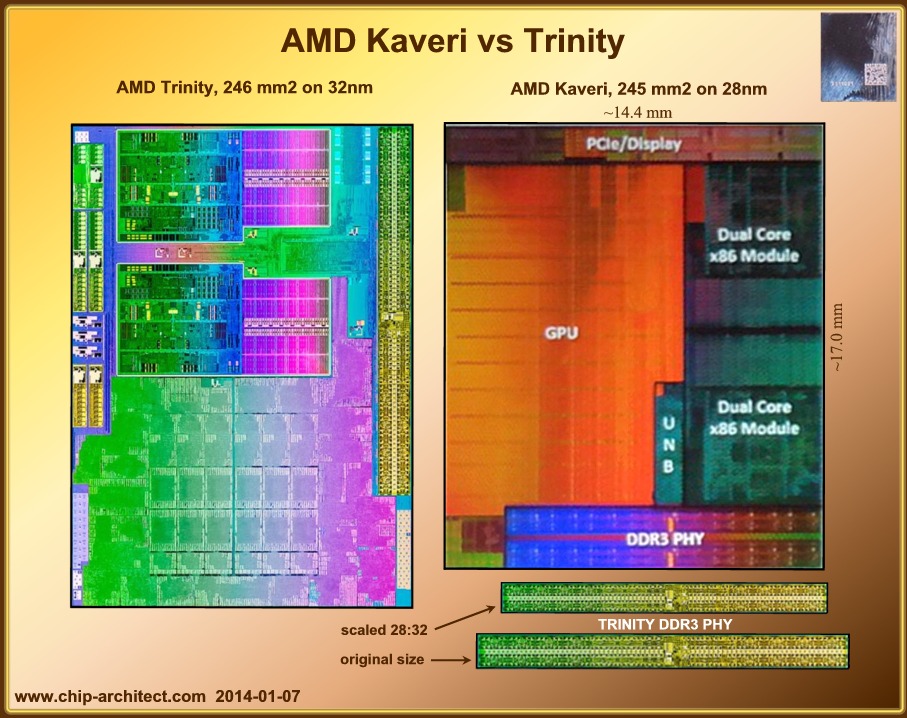
Sasha ha scritto:ho fatto un veloce confronto sul numero di transistor usati e l'area occupata rispetto ai predecessori… Liano: 228 mm2, with 1.178 billion transistor (GloFo 32nm SOI) = 5,167mln transistors/mm2 Trinity: 246 mm2, 1.303 Billion transistors (GloFo 32nm SOI) = 5,296 mln transitors/mm2 Kaveri: 245 mm2, 2.41 Billion transistors (GloFo 28nm Bulk SHP) = 9,837 mln transistors/mm2 Sandy Bridge: 216 mm2, 1.16 Billion transistors (Intel 32nm planare double-gate) = 5,370 mln transistors/mm2 Ivy Bridge: 160 mm2, 1.4 Billion transistors (Intel 22nm TriGate) = 8,750 mln transistors/mm2 Haswell: 177 mm2, 1.4 Billion transistors (Intel 22nm TriGate) = 7,910 mln transistors/mm2
Non mi pare che i memory controller intel con quad channel abbiano quell'aspetto...
A me sembrano proprio due controller distinti, il che avrebbe un senso: un degli aspetti fondamentali di HSA è il fornire un accesso unificato alla memoria virtuale per la cpu e la gpu.
Con un solo controller le operazioni parallele divengono impossibili, indipendentemente se cpu e gpu debbano lavorare su are di memoria diverse, uguali (buffer intero o sub-buffer). Sarebbe come adesso (anzi peggio) visto che se uno dei due lavora, l'altro si gira i pollici (per non parlare dell'overhead di sincronizzazione), ovvero la parallelizzazione fra lavoro di cpu e gpu andrebbe a farsi benedire.
Certo si potrebbe implementare uno scheduler, ma questo non farebbe che spezzettare i vari lavori in task, aggiungendo solo un sacco di overhead aggiuntivo.
Con due controller invece è vero che cpu e gpu non potrebbero in ogni caso lavorare in parallelo sulla stessa area di memoria (è ovvio che è impossibile), ma sarebbe comunque possibile farli lavorare in contemporanea su buffer diversi o anche su sub-buffer di un buffer comune, i tempi di sincronizzazione sarebbero ridotti, e l'overhead minore.
Il problema si ridurrebbe a come non far accedere i due controller allo stesso indirizzo di memoria, ma questo potrebbe essere gestito abbastanza facilmente (ad esempio da una piccola cache contenente indirizzi, gli indici di inizio e fine delle are di memorie interessata, sufficientemente grande per il numero di core di cpu, e le unità di calcolo della gpu, quindi di dimensioni abbastanza contenute, il che permetterebbe di avere una piccola cache abbastanza veloce e ad un costo relativamente contenuto).
Alessio89 ha scritto:Non mi pare che i memory controller intel con quad channel abbiano quell'aspetto...
A me sembrano proprio due controller distinti, il che avrebbe un senso: un degli aspetti fondamentali di HSA è il fornire un accesso unificato alla memoria virtuale per la cpu e la gpu.
Con un solo controller le operazioni parallele divengono impossibili, indipendentemente se cpu e gpu debbano lavorare su are di memoria diverse, uguali (buffer intero o sub-buffer). Sarebbe come adesso (anzi peggio) visto che se uno dei due lavora, l'altro si gira i pollici (per non parlare dell'overhead di sincronizzazione), ovvero la parallelizzazione fra lavoro di cpu e gpu andrebbe a farsi benedire.
Certo si potrebbe implementare uno scheduler, ma questo non farebbe che spezzettare i vari lavori in task, aggiungendo solo un sacco di overhead aggiuntivo.
Con due controller invece è vero che cpu e gpu non potrebbero in ogni caso lavorare in parallelo sulla stessa area di memoria (è ovvio che è impossibile), ma sarebbe comunque possibile farli lavorare in contemporanea su buffer diversi o anche su sub-buffer di un buffer comune, i tempi di sincronizzazione sarebbero ridotti, e l'overhead minore.
Il problema si ridurrebbe a come non far accedere i due controller allo stesso indirizzo di memoria, ma questo potrebbe essere gestito abbastanza facilmente (ad esempio da una piccola cache contenente indirizzi, gli indici di inizio e fine delle are di memorie interessata, sufficientemente grande per il numero di core di cpu, e le unità di calcolo della gpu, quindi di dimensioni abbastanza contenute, il che permetterebbe di avere una piccola cache abbastanza veloce e ad un costo relativamente contenuto).
Facci una news dove spieghi la cosa.
Non vorrai fare come con le APU x86 di PS4 e XB1?
PC: CoolerMaster MasterBox Q300P, AMD Ryzen 7 5800X, Thermalright Peerless Assassin 120 SE, GIGABYTE B550M AORUS ELITE, 2x32GB Patriot Viper DDR4-3600, Asus Dual RX6650XT 8GB, SSD Toshiba RC500 512GB, SSD Lexar NM790 2TB, CoolerMaster V650 Gold, Windows 11 Home
È solo quello che mi sembra... Per l'apu di di x1 avevo delle librerie come prove, qua non ho niente, semplicemente mi pare che avere due controller magari anche con una piccola cache mi sembra più semplice, meno costoso ed efficace che avere subito un unico controller, soprattutto se pensiamo a come è messa AMD a livello di denaro.
Per carità una soluzione unica, magari con un quad channel, sarebbe bellissimo ma semplicemente la vedo improbabile, anche perché altrimenti l'avrebbero sbandierata ai quattro venti come cavallo di battaglia.
Sasha ha scritto:A quasi un anno (10 mesi) di distanza dalla presentazione, e con Mullin/Beema alle porte
Le porte rimarranno chiuse a quanto pare...
Tanto anche intel, per il successore di bay trail desktop te voja, fine 2015 come minimo.
Che poi non le ho mai viste in vendita le mobo con i pentium/atom.
si, ma... A questo punto preferisco la filosofia Intel... l'LGA2011 ha un anno di distanza dalla versione consumer... Ma almeno quando lo presentano è subito in commercio... Così, fa un pò ridere
Idem comunque, neanche io ho visto Bay trail disponibile sul mercato...






{kind=link}