Cercare d'incrementare il rapporto performance-per-watt è fondamentale per un produttore di chip elettronici. Questo concetto è stato ribadito da Jen-Hsun Huang, presidente e CEO di NVIDIA, durante la GPU Technology Conference di settembre 2010 per introdurre la roadmap con le future architetture grafiche che la casa di Santa Clara avrebbe presentato dopo la generazione di "GPU Fermi" ed è stato altresì utilizzato da Tom Petersen, direttore del technical marketing dell'azienda, per svelare la GeForce GTX 680 nel corso dell'Editor's Day di Parigi lo scorso 14 marzo, evento al quale eravamo presenti anche noi di Bits and Chips.
Kepler, il nome dell'architettura alla base della GeForce GTX 680, propone le novità che NVIDIA ha deciso di apportare per migliorare l'efficienza delle proprie GPU. Non siamo di fronte ad una rivoluzione, ma neanche ad un semplice die-shrik di Fermi con la nuova tecnologia a 28nm. Prendendo in prestito la terminologia utilizzata da Intel per descrivere le CPU Ivy Bridge possiamo dire che Kepler è un "tock+".
Con la GeForce GTX 480, per ottenere il primato delle performance NVIDIA si era scontrata con il problema dell'eccessivo consumo energetico, soprattutto nei confronti della soluzione concorrente, problema risolto in parte con il rilascio della GeForce GTX 580. Con la GeForce GTX 680 l'approccio è diverso: privilegiare il rapporto performance-per-watt e raggiungere un elevato livello prestazionale grazie ad un sapiente lavoro di ottimizzazioni hardware e software. Ricordiamo che NVIDIA è un'azienda che vende harware ma ha anche forte esperienza nel campo software, nel quale investe costantemente. Proprio dalla stretta collaborazione del team hardware con quello software è nata la GeForce GTX 680, scheda identificata con il nome in codice GK104.

Quali sono le novità implementate per raggiungere questo obiettivo? Si parte da una rivisitazione dell'organizzazione dello Streaming Multiprocessor rispetto a Fermi che ha portato all'abbandono del cosiddetto "hot-clock" in favore di un elevato numero di shader (o CUDA Core), passando per l'introduzione della funzione GPU-boost che regola dinamicamente la frequenza di clock in base al TDP, a nuove tecniche di filtraggio e ottimizzazioni lato driver, fino ad arrivare all'utilizzo un sistema di raffreddamento più efficiente, abbinato a scelte peculiari sulla disposizione dei componenti presenti sul PCB. Il tutto sfruttando il nuovo processo produttivo a 28 nanometri di TSMC che ha permesso d'integrare ben 3,56 miliardi di transistor in 294mm^2.

(logo rinnovato per la serie GeForce GTX 600 di NVIDIA)
L'architettura Kepler
La nuova architettura Kepler trova nelle schede GeForce GTX 680 la sua prima implementazione reale. Partendo dalle basi create nel 2010 con il lancio delle prime schede grafiche Fermi della serie GeForce GTX 480, l'architettura parallela ottimizzata per tessellation, displacement mapping e GPU computing si rinnova oggi con Kepler puntando proprio su quelle caratteristiche che pubblico e critica non avevano molto gradito.
Per migliorare l'efficienza della GPU l'azienda di Santa Clara ha lavorato su più fronti: l'ottimizzazione dell'architettura, l'utilizzo di un processo produttivo avanzato e l'integrazione di apposite feature. Trattandosi comunque di una evoluzione, le similitudini di Kepler con Fermi sono davvero molte.
Kepler è composta da diversi blocchi hardware progettati ognuno per assolvere ad uno specifico compito. I blocchi a più basso livello sono raggruppati all'interno di blocchi logici che vedono nel Graphics Processing Clusters (GPC) il loro raggruppamento di più alto livello. Un blocco GPC dispone di tutte le necessarie risorse dedicate per le operazioni di raster, shading, texture e calcolo, tanto che la maggior parte delle funzioni della pipeline grafica sono eseguite proprio all'interno di uno o più GPC.
 Schema a blocchi di Kepler
Schema a blocchi di Kepler
Nelle schede GeForce GTX 680 sono previste 4 GPC ognuna con un raster engine dedicato e due unità Streaming Multiprocessor di nuova generazione (SMX): in totale sono presenti dunque 8 SMX che portano in dote ben 1536 CUDA Cores. Nonostante un paragone diretto con le unità di calcolo elementari della rivale architettura AMD Cayman non possa essere fatto tout-court, il vedere esattamente lo stesso numero di stream processor Cayman XT suona quantomeno strano!
Ma probabilmente le somiglianze fra le due architetture non vanno oltre vista, ad esempio, l'inversione di tendenza di entrambi i produttori sulla gestione delle memorie. Se finora NVIDIA ha puntato su un bus molto ampio abbinato a chip funzionanti a frequenza più bassa, con le GeForce GTX 680 il bus delle memorie torna ad essere di "soli" 256-bit mentre le memorie GDDR5 raggiungono ben 6008MHz effettivi, un record assoluto. Il contrario è successo in casa AMD, conservativa sul fronte bus fino a prima delle architetture GCN ma ora salita fino a 384-bit.
Per soddisfare la fame di dati delle unità di calcolo, per ogni memory controller NVIDIA ha previsto 128KB di cache L2 mentre 8 ROP garantiscono il processamento di altrettanti campioni. Per realizzare un bus a 256-bit, NVIDIA ha utilizzato quattro controller per un totale, nelle GeForce GTX 680, di 512KB di cache L2 e 32 ROP. La cache L2 unificata di Kepler permette a tutte le unità di comunicare e scambiarsi dati e, rispetto a Fermi, offre una banda dati superiore del 73%.
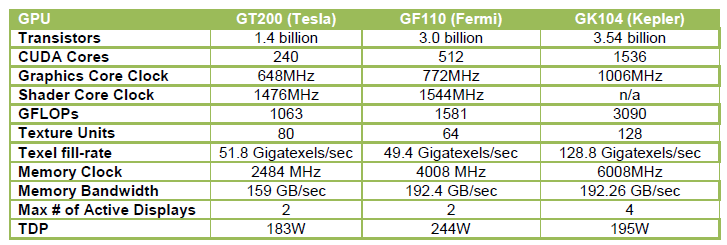
Rispetto alla precedente architettura Fermi, i numeri di Kepler sono ben più "pesanti" ma quel che vogliamo notare è il fatto che la banda di memoria sia rimasta esattamente la stessa (Kepler ha memorie più veloci ma un bus meno ampio di Fermi che aveva 6 memory controller) e che i consumi siano nettamente diminuiti, tornando ai livelli di quelli della vecchia Tesla GT200.
Visto che il blocco più importante dell'architettura Kepler è quello indicato con GPC analizziamolo più in dettaglio confrontandolo anche con quello di Fermi. Come già detto Kepler contiene 4 GPC che permettono di elaborare 32 pixels per ciclo di clock. All'interno di ogni GPC di Kepler sono presenti due SMX invece dei quattro disponibili nei GPC di Fermi ma ognuno di essi dispone di un maggior numero di unità rispetto al passato.

Blocco Streaming Multiprocessor di Kepler
 Blocco GPC di Fermi
Blocco GPC di Fermi
I singoli blocchi presenti all'interno di ogni SMX non sono cambiati molto rispetto a quelli di Fermi tranne alcune eccezioni. I CUDA cores continuano a gestire le operazioni di pixel, vertex e geometry shading oltre ai calcoli relativi alla fisica ed al GPU computing, le texture unit continuano ad occuparsi dei filtri e le unità LD/ST di caricare e salvare i dati in memoria. Esistono, come in Fermi, delle SFU o Special Function Units che si occupano principalmente di calcoli speciali come quelli trascendentali o di interpolazione.
 Fermi vs. Kepler
Fermi vs. Kepler
Anche il blocco PolyMorph Engine, che raggiunge la versione 2.0, è ancora presente seppure con le dovute ottimizzazioni. Questa unità è responsabile in particolare della gestione delle operazioni di tessellation ed è stata migliorata in modo da cercare di evitare penalizzazioni pesanti sulle performance di rendering a causa di un fattore di tessellation elevato.

L'idea di NVIDIA è quella di supportare gli sviluppatori anche per il prossimo futuro quando e se essi decideranno di migliorare la qualità della tessellation utilizzando un maggior numero di triangoli. Non deve ingannare il fatto che rispetto a Fermi il numero di PolyMorph Engine è dimezzato (8 contro 16): le unità di Kepler garantiscono prestazioni per clock circa doppie e queste, unite alla frequenza di funzionamento del chip ben più elevata, fa si che complessivamente si possano ottenere prestazioni del 30% circa superiori.
NVIDIA afferma che le ottimizzazioni apportate sia sulla composizione del blocco SMX stesso che sulle singole unità, permette a Kepler di ottenere non solo un vantaggio prestazionale rispetto a Fermi, ma anche una maggiore efficienza. Il produttore ha poi sapientemente combinato un maggior numero di unità con frequenze più elevate per far si che, dove il throughput per-clock non risulti superiore, ci pensa la frequenza di funzionamento.
In realtà quanto detto non è del tutto esatto: se la frequenza del chip è stata incrementata portandola oltre la soglia del GHz (forse anche in risposta ai proclami di AMD di poche settimane fa), NVIDIA ha abbandonato l'idea di avere una doppia frequenza (una per il chip ed una per gli shader).

Una delle prime differenze che saltano all'occhio guardando l'architettura Kepler per le GeForce GTX 680 è che il numero totale di SMX è pari ad 8 invece che a 16 come succede per le GeForce GTX 580. La motivazione di questa scelta sta nel cercare di migliorare l'efficienza del chip creando un minor numero di blocchi che racchiudano più unità e riescano a fornire prestazioni superiori.
Per garantire il flusso di dati necessario alle unità di esecuzione del blocco SMX vengono utilizzati quattro warp scheduler ognuno capace di fornire due istruzioni per ciclo di clock, esattamente come accadeva con Fermi. In Kepler, però, queste unità sono state riprogettate per migliorarne l'efficienza e, a fronte degli stessi blocchi hardware per gestire le stesse funzioni, è stata ridotta la complessità di quegli stadi che tutto sommato non apportano un vantaggio reale ma - di contro - consumano molto.
Seguendo gli stessi principi è stato migliorato il singolo processor execution core sul quale sono state apportate modifiche in ottica di riduzione delle connessioni e massimizzazione dell'efficienza del clock gating.
Questo è esattamente quanto dicevamo in precedenza circa l'eliminazione dello shader clock, feature introdotta nell'architettura Tesla come parametro di ottimizzazione dell'area del chip. In pratica, visto che la tecnologia di produzione di quel tempo non permetteva di integrare un maggior numero di transistor in un chip, per ottenere il throughput che NVIDIA si era prefissata, la frequenza di funzionamento di tali unità è stata raddoppiata rispetto alla frequenza del chip.

Basta un semplice calcolo per capire che questa scelta porta a consumi 4 volte superiori per quelle unità. Un clock doppio implica anche il raddoppio degli stadi di pipeline, ognuno funzionanti al doppio della frequenza nominale, il che porta complessivamente ad assorbimenti 2x2 volte superiori. Anche se Kepler dispone di un numero di unità doppie ciò comporta consumi "solo" doppi, recuperando un fattore due rispetto a Fermi. Perciò in questo caso, anche grazie al più avanzato processo produttivo, NVIDIA ha scelto un'ottimizzazione in termini di potenza invece che in termini di area.
Le novità fra TXAA, GPU Boost e NVENC
L'arrivo di una nuova architettura è sempre accompagnato da nuove feature software e hardware tanto per AMD come per NVIDIA. Questa volta l'elenco comprende:
- GPU Boost: feature hardware, disponibile solo con le nuove VGA GeForce GTX 680
- Adaptive VSync: feature software, disponibile con tutte le VGA GeForce utilizzando i nuovi drivers GeForce 3xx
- FXAA e TXAA: feature software, disponibile con tutte le VGA GeForce utilizzando i nuovi drivers GeForce 3xx
- Bindless Textures: feature hardware, disponibile con le nuove VGA GeForce GTX 680 e con appliativi OpenGL
- NVENC: feature hardware, disponibile solo con le nuove VGA GeForce GTX 680
GPU Boost
Al pari delle moderne CPU Intel ed AMD, NVIDIA ha deciso di regalare alle sue nuove GPU un sistema di boost prestazionale automatico che incrementa la frequenza di funzionamento del chip, quando esiste la possibilità di farlo. L'idea è sempre la stessa: fissato un limite massimo per la potenza assorbita, quando il caso reale fa si che non lo si raggiunga, la GPU ha uno "spazio" a disposizione per incrementare le sue prestazioni.

In parole povere, NVIDIA ha fissato un limite massimo per la potenza assorbita da questa scheda impostando un determinato TDP (thermal design power) e su questo ha stabilito un valore di frequenza nominale, pari a 1006MHz, per la GTX 680. Questi dati implicano che, a quella frequenza e con una determinata tensione di funzionamento, la massima dissipazione del chip grafico deve essere quella indicata dal TDP.
Se però ci mettiamo in un caso pratico di un gioco che sta girando, non sempre tutte le unità del chip grafico sono coinvolte e, anche se la frequenza è quella massima possibile di 1006MHz, la tensione è quella prevista, non è detto che i consumi del chip siano quelli massimi imposti dal TDP. In tali casi è dunque possibile incrementare la frequenza di funzionamento e se necessario anche la tensione per ottenere maggiori prestazioni.

Il funzionamento deve essere ovviamente dinamico (se fosse stata impostata una frequenza di funzionamento superiore fissa sarebbe stato necessario innalzare il limite di TDP) e controllato in real time. Questo è proprio quanto fa NVIDIA con Kepler nel quale è stata integrata una circuiteria hardware che continuamente controlla i consumi della GPU, evitando perciò di dover ricorrere a specifici (e statici) profili per ogni applicazione.

Dal clock di base in modalità 3D di 1006MHz, le schede GeForce GTX 680 possono così raggiungere un “Boost Clock” di almeno 1058MHz (nel momento in cui i consumi dell'applicazione che sta girando lo permettono). Il massimo clock raggiunto potrebbe essere però superiore a questo se la GPU ha ancora spazio a disposizione per salire. Il produttore afferma di aver osservato incrementi anche fino ad 1,1GHz.
GPU Boost, infine, è pienamente compatibile con le pratiche di overclock. Per aumentare la frequenza di base della GPU, sia nel caso in cui venga effettuato dai partners AIB sia quando venga effettuato dall'utente finale utilizzando uno dei tanti tool software a disposizione, è necessario prima modificare il target di potenza della GPU che, a quel punto, risucirà a raggiungere anche più elevati valori di Boost Clock. Il funzionamento è molto simile a quello che incontriamo con le schede grafiche della rivale AMD.

Adaptive VSync
Per risolvere i problemi di qualità delle immagini dovuti al sincronismo fra il framerate ed il refresh dei display, NVIDIA ha ideato una tecnologia indicata come Adaptive VSync, la quale risulta disponibile per tutte le schede grafiche GeForce grazie ai nuovi drivers della serie 300. Il problema dello stuttering, dovuto al VSync, si presenta con determinati videogame ed in determinate situazioni: purtroppo non è risolvibile in maniera definitiva attivando o disattivando il VSync dai drivers della scheda grafica come si fa ormai da sempre.

La disattivazione del VSync apporta i maggiori benefici solo quando il framerate è inferiore a 60 frame al secondo: così facendo si evita che la sincronizzazione salti di colpo da 60Hz a 30Hz o a valori inferiori (multipli di 60). Quando però il framerate è superiore a 60, mantenere il VSync disattivato crea fastidiose linee orizzontali che risultano maggiormente visible all'aumentare degli fps. In questo caso sarebbe perciò meglio avere il VSync attivato.

NVIDIA ha dunque pensato di rendere dinamica l'attivazione e la disattivazione del VSync attraverso la tecnologia Adaptive VSync. Quando il framerate scende sotto i 60 frame al secondo il VSync viene disattivato mentre viene attivato quando sale sopra i 60 fps. Nel pannello di controllo dei drivers NVIDIA esistono due modalità per Adaptive VSync (Adaptive e Adaptive (half refresh rate)) che hanno come limite 60Hz e 30Hz.

Due nuove tecniche di AA: FXAA e TXAA
Quello delle tecniche di AntiAliasing è un terreno di discussione ancora molto fertile nonostante se ne parli e lo si affronti ormai da anni. La tecnica indicata come FXAA è già disponibile all'interno di alcuni giochi e, vista la sua indubbia efficienza, NVIDIA ha pensato di supportarla al meglio implementandola all'interno dei drivers (questo permette di applicarla a qualunque gioco).
La tecnica di FXAA è basata su un filtro di pixel shading applicato alla fine del processo di creazione delle scene assieme ad altri filtri di post processing come quelli di motion blur o bloom. I vantaggi sono relativi sia alle prestazioni che all'uso della memoria rispetto alle tecniche di multi-sample anti-aliasing (MSAA) e, come se non bastasse, il filtro permette di agire sia sull'edge aliasing che sull'aliasing per single-pixel e sub-pixel con una riduzione importante dello shader aliasing. Possiamo affermare che la qualità del filtro FXAA è simile a quella della tecnica MSAA 4x al costo di un MSAA 2x.
Nei drivers della serie 300 è supportata la modalità FXAA che rispecchia un mix delle tecniche FXAA 1 (disponibile ad esempio in Age of Conan, F.E.A.R.3 e Duke Nukem Forever) e FXAA 3 (Battlefield 3) che fornisce una migliore combinazione fra performance e qualità delle immagini e funziona con applicazioni DirectX 9, DirectX 10, DirectX 11 e OpenGL. Il mix proposto da NVIDIA migliora la risposta sul testo rispetto all'FXAA 1 e la qualità delle immagini rispetto all'FXAA 3 che però risulta a sua volta superiore su HUD e testo.
La tecnica di TXAA è invece del tutto nuova ed è stata progettata per avvantaggiarsi in pieno delle performance delle GeForce GTX 680 con high FP16 texture. TXAA è un insieme di filtri di anti-aliasing hardware, stadi custom di CG AA resolve "film style" e un componente temporale (applicato solo nel caso di TXAA 2x). In sostanza il TXAA è un resolve filter di elevata qualità progettato per funzionare correttamente con la pipeline di post processing HDR.
TXAA è dipsonibile in due modalità, TXAA 1 e TXAA 2. Il primo offre una qualità visiva simile a quella di una tecnica di MSAA 8x con un pegno prestazionale vicino a quello di un MSAA 2x; il TXAA 2 costa quanto un MSAA 4x ma la qualità è superiore a quella di un MSAA 8x.

I primi giochi ad utilizzare le tecniche di TXAA saranno disponibili entro l'anno ed includeranno: MechWarrior Online, Secret World, Eve Online, Borderlands 2, Unreal 4 Engine, BitSquid, Slant Six Games e Crytek.



Bindless Texture
Finora la gestione delle texture è stata legata ad una tabella di riferimenti che, con le DirectX 11, permette di utilizzare 128 slot e dunque altrettante texture simultaneamente. Questo numero è esattamete lo stesso che troviamo nelle architetture Fermi mentre con Kepler e le bindless texture, è possibile utilizzare contemporaneamente quante texture si desidera (il limite è spostato ad oltre un milione) perché lo shader può referenziare le texture direttamente in memoria.

Le bindless texture sono per ora utilizzabili solo con applicazioni OpenGL ma si prevede che essere saranno disponibili anche con le DirectX in maniera nativa o attraverso una API NVIDIA (NVAPI).
NVENC
All'interno di Kepler NVIDIA ha integrato un apposito modulo per la gestione in hardware della codifica dei video H.264. NVENC, che ricorda da vicino la tecnologia Intel Quick Sync Video, permette di effettuare queste operazioni con consumi decisamente ridotti e con velocità fino a 8x rispetto al video in real time: ciò significa che, se dovete codificare un video di 32 minuti vi saranno necessari appena 4 minuti.
In precedenza, con architettura CUDA based, la stessa operazione poteva essere effettuata da un programma software capace di sfruttare i CUDA Core che, nonostante l'eccezionale incremento prestazionale rispetto ad una CPU tradizionale, non risulta efficiente quanto il nuovo modulo di Kepler. Questo offre prestaizoni 4 volte superiori con consumi inferiori. In aggiunta NVENC può lavorare in parallelo con un encoder CUDA senza avere rispercussioni sulle prestazioni (tranne nel caso i cui qualche algoritmo di pre-processing richiede CUDA per il suo funzionamento).
NVENC supporta i profili H.264 Base, Main ed High Profile Level 4.1 (come nello standard Blu-ray), supporta la codifica MVC (Multiview Video Coding) per i video stereoscopici usati nei Blu-ray 3D e permette di codificare video fino alla risoluzione di 4096x4096 pixel. I possibili utilizzi di NVENC riguardano la realizzazione di videoconferenze HD su notebook mainstream, l'invio di contenuti in alta definizione da un PC desktop verso schermi TV attraverso una rete wireless o il semplice authoring di dischi Blu-ray.

La GeForce GTX 680 mantiene il formato doppio slot, ma con i suoi 25.4 centimetri è la GTX x80 più compatta mai realizzata da Nvidia. Frontalmente ricorda la GTX 470, per via della posizione decentrata (verso l'alto) della ventola di raffreddamento, con una differenza: il particolare design dei connettori di alimentazione esterna. Il dissipatore di calore è completamente nascosto da una copertura in plastica.

Vista da dietro la scheda svela un disposizione curata dei componenti che serve a facilitare la dissipazione termica posteriore. In alto a sinistra spicca il mini-PCB che contiene il regolatore di tensione. Invece d'integrarlo nVidia ha preferito acquistare separatamente il blocco completo dal produttore e "saldarlo" direttamente sul PCB Master. Questa scelta ha permesso di contenere i costi relativi allo sviluppo e all'adattamento del componente.

Rimovendo la copertura in plastica scopriamo le parti che compongono il sistema di raffreddamento: dissipatore vero e proprio, placca metallica e ventola a turbina. Quest'ultima ha una nuova conformazione delle pale e del supporto atta a produrre meno vibrazioni durante il funzionamento.

Il dissipatore prevede un sistema di heatpipe integrato nella base, a diretto contatto con le sottili lamelle in alluminio. Le alette hanno un profilo sagomato che oltre ad incrementare la superficie di dissipazione accelera il flusso d'aria spinto dalla ventola e ne facilita l'espulsione verso la zona anteriore.

Il circuito stampato pur non essendo estremamente complesso lascia intravedere l'ottimo lavoro degli ingegneri Nvidia per sfruttare al meglio lo spazio a disposizione. La sezione di alimentazione è stata ruotata di 90°, come sulla GTX 470, ma questa volta per non essere costretta ad utilizzare una ventola più piccola Nvidia ha modificato l'orientamento dei 2 connettori PCIe 6-pin, che ora non risultano più "uno di fianco all'altro" ma "uno sull'altro" (tower design).

La circuiteria di alimentazione è a 4+2 fasi (4 per la GPU e 2 per le memorie video). Il chip grafico GK104 è privo del classico IHS di protezione: a memoria la casa di Santa Clara non utilizzava una soluzione del genere per una GPU di fascia alta dai tempi del G92. Esso è circondato dagli 8 chip di memoria GDDR5, ciascuno da 256MB di capacità.

La griglia per lo sfogo dell'aria calda soffiata dalla ventola sul dissipatore di calore è affiancata da due connettori DVI, un connettore HDMI e un connettore Display Port. Per la prima volta Nvidia consente di pilotare più di 2 monitor contemporaneamente su una scheda video a singola GPU, ora sono supportate configurazioni fino a 4 monitor. In questo caso la casa di Santa Clara si è finalmente allineata alla rivale AMD che ha implementato questo genere di supporto tre generazioni fa, con la serie Radeon HD 5000.


Tradotto per gli appassionati dei prodotti del marchio del camaleonte verde questo significa che adesso possono realizzare sistemi multi-monitor con tecnologia Nvidia Surround e NVIDIA 3D Vision Surround utilizzando una sola GTX 680.
Ovviamente Nvidia ha approfittato di questa "novità" per proporre diverse feature di contorno:



GeForce GTX 680 in cifre
Riassumiamo nella tabella seguente le caratteristiche tecniche della nuova VGA NVIDIA confrontate con quelle di altri modelli già noti.
|
Caratteristiche tecniche schede video |
|||||
|
GeForce GTX 680 |
GeForce GTX 580 |
Radeon HD 6970 |
Radeon HD 7950 |
Radeon HD 7970 |
|
|
Sigla GPU |
GK104 |
GF110 |
Cayman XT |
Tahiti PRO |
Tahiti XT |
|
Numero ALU/shader |
1536 |
512 |
1536 |
1792 |
2048 |
|
Processo produttivo |
28nm |
40nm |
40nm |
28nm |
28nm |
|
Transistor |
3,54 miliardi |
~3 miliardi |
2,64 miliardi |
4,31 miliardi |
4,31 miliardi |
|
Dimensioni del die |
294mm2 |
520mm2 |
389mm2 |
365mm2 |
365mm2 |
|
Frequenza (boost) GPU |
1006 (1058)MHz |
772MHz |
880MHz |
800MHz |
925MHz |
|
Frequenza shader |
1006MHz |
1544MHz |
880MHz |
800MHz |
925MHz |
|
Interfaccia memorie |
256-bit |
384-bit |
256-bit |
384-bit |
384-bit |
|
Frequenza memorie |
1502MHz |
1000MHz |
1375MHz |
1250MHz |
1375MHz |
|
Freq. mem. effettiva |
6,008GHz |
4GHz |
5,5GHz |
5GHz |
5,5GHz |
|
Tipo di memoria |
GDDR5 |
GDDR5 |
GDDR5 |
GDDR5 |
GDDR5 |
|
Banda di memoria |
192,26GB/s |
192GB/s |
176GB/s |
240GB/s |
264GB/s |
|
Quantità memoria |
2048MB |
1536MB |
2048MB |
3072MB |
3072MB |
|
Interfaccia |
PCIe 3.0 |
PCIe 2.1 |
PCIe 2.1 |
PCIe 3.0 |
PCIe 3.0 |
|
Alimentazione supplementare |
2x6-pin |
-1x6-pin |
-1x6-pin |
2x6-pin |
-1x6-pin |
|
Numero slot occupati |
2 |
2 |
2 |
2 |
2 |
|
TDP |
195W |
244W |
250W |
200W |
250W |
A quanto detto sinora vogliamo solo aggiungere, guardando i numeri inseriti in tabella che NVIDIA è risucita ad utilizzare un minor numero di transistori rispetto alle nuove GPU della rivale AMD probabilmente grazie all'adozione di un bus delle memorie meno ampio il quale ha comunque delle ripercussioni sulla banda dati, pari a 264GB/s per le Radeon HD 7970 e a 193GB/s circa per le GeForce GTX 680. L'apparente minore complessità del chip, testimoniata anche da una minore supericie del chip stesso, e probabilmente le ottimizzazioni introdotte da NVIDIA hanno garantito un TDP decisamente inferiore di quello delle 7970, addirittura più basso anche di quello delle Radeon HD 7950, nonostante la frequenza di funzionamento del chip risulti essere superiore.
Conclusioni
Molta attesa era stata riservata a questa scheda per motivi di varia natura. Intanto AMD ha già dispiegato tutte le sue forze nel segmento medio e alto del mercato con le sue proposte Radeon HD 7000 e, approfittando del mercato ha deciso i prezzi di vendita quasi in situazione di monopolio. Inoltre, almeno fino alle ultime settimane, NVIDIA è stata brava a non far trapelare nulla o quasi circa caratteristiche, prezzi e data di presentazione delle nuove VGA.
La curiosità degli appassionati è stata ulteriormente stimolata dal sapere che questa nuova GPU avrebbe utilizzato il processo produttivo a 28nm e che avrebbe introdotto diverse nuove feature. Tutti felici e contenti? Beh di carne al fuoco ce n'è davvero molta, tanto che siamo certi che le nostre prove richiederanno ancora del tempo per essere completate come più ci piace.
Le novità introdotte da NVIDIA nell'architettura Kepler sembrano essere sulla carta molto interessanti con ottimizzazioni che partono da giustificazioni calate sulla realtà e nate dall'osservazione dei problemi incontrati in precedenza. Le solide fondamenta gettate con Fermi hanno garantito al produttore il poter lavorare senza dover sconvolgere nulla ma applicando semplicemente una mano "di lucido" per ottenere risultati che paiono davvero eccellenti. Basti pensare al fatto che alla Game Developers Conference di San Francisco dello scorso anno per far girare la demo di Epic, Samaritan, erano state utilizzate 3 VGA GeForce GTX 580 in modalità 3-way SLI contro una sola GeForce GTX 680 utilizzata allo stesso evento di quest'anno.

NVIDIA ha lavorato per migliorare ulteriormente prestazioni e qualità grafica implementando nuove caratteristiche come la tecnologia GPU Boost, che permette di incrementare la frequenza di funzionamento del chip grafico di almeno il 5%, oppure l'Adaptive VSync per evitare problemi di tearing o stutter. E ancora, l'arrivo di nuove tecniche di AA come la già nota FXAA, adesso disponibile nel pannello dei drivers, o la nuova TXAA che promette qualità elevata con uno scotto prestazionale minimo non può che far piacere, così come il nuovo modulo di codifica video H.264 NVENC.
Novità a parte, NVIDIA ha rifinito anche tutto quanto era già disponibile con le precedenti serie di schede grafiche, a partire dal supporto video per la gestione, ora, di 4 display contemporaneamente e della modalità 3D Vision Surround con una sola GeForce GTX 680.
Il prezzo della GeForce GTX 680 suggerito dal produttore, è pari a 506,99 Euro (IVA inclusa) per il nostro mercato con disponibilità immediata presso i rivenditori ufficiali. Questo prezzo è inferiore a quello proposto da AMD per la Radeon HD 7970 al lancio: probabilmente nei prossimi giorni assisteremo ad una risposta dal parte dell'azienda di Sunnyvale.