L'architettura Kepler
La nuova architettura Kepler trova nelle schede GeForce GTX 680 la sua prima implementazione reale. Partendo dalle basi create nel 2010 con il lancio delle prime schede grafiche Fermi della serie GeForce GTX 480, l'architettura parallela ottimizzata per tessellation, displacement mapping e GPU computing si rinnova oggi con Kepler puntando proprio su quelle caratteristiche che pubblico e critica non avevano molto gradito.
Per migliorare l'efficienza della GPU l'azienda di Santa Clara ha lavorato su più fronti: l'ottimizzazione dell'architettura, l'utilizzo di un processo produttivo avanzato e l'integrazione di apposite feature. Trattandosi comunque di una evoluzione, le similitudini di Kepler con Fermi sono davvero molte.
Kepler è composta da diversi blocchi hardware progettati ognuno per assolvere ad uno specifico compito. I blocchi a più basso livello sono raggruppati all'interno di blocchi logici che vedono nel Graphics Processing Clusters (GPC) il loro raggruppamento di più alto livello. Un blocco GPC dispone di tutte le necessarie risorse dedicate per le operazioni di raster, shading, texture e calcolo, tanto che la maggior parte delle funzioni della pipeline grafica sono eseguite proprio all'interno di uno o più GPC.
 Schema a blocchi di Kepler
Schema a blocchi di Kepler
Nelle schede GeForce GTX 680 sono previste 4 GPC ognuna con un raster engine dedicato e due unità Streaming Multiprocessor di nuova generazione (SMX): in totale sono presenti dunque 8 SMX che portano in dote ben 1536 CUDA Cores. Nonostante un paragone diretto con le unità di calcolo elementari della rivale architettura AMD Cayman non possa essere fatto tout-court, il vedere esattamente lo stesso numero di stream processor Cayman XT suona quantomeno strano!
Ma probabilmente le somiglianze fra le due architetture non vanno oltre vista, ad esempio, l'inversione di tendenza di entrambi i produttori sulla gestione delle memorie. Se finora NVIDIA ha puntato su un bus molto ampio abbinato a chip funzionanti a frequenza più bassa, con le GeForce GTX 680 il bus delle memorie torna ad essere di "soli" 256-bit mentre le memorie GDDR5 raggiungono ben 6008MHz effettivi, un record assoluto. Il contrario è successo in casa AMD, conservativa sul fronte bus fino a prima delle architetture GCN ma ora salita fino a 384-bit.
Per soddisfare la fame di dati delle unità di calcolo, per ogni memory controller NVIDIA ha previsto 128KB di cache L2 mentre 8 ROP garantiscono il processamento di altrettanti campioni. Per realizzare un bus a 256-bit, NVIDIA ha utilizzato quattro controller per un totale, nelle GeForce GTX 680, di 512KB di cache L2 e 32 ROP. La cache L2 unificata di Kepler permette a tutte le unità di comunicare e scambiarsi dati e, rispetto a Fermi, offre una banda dati superiore del 73%.
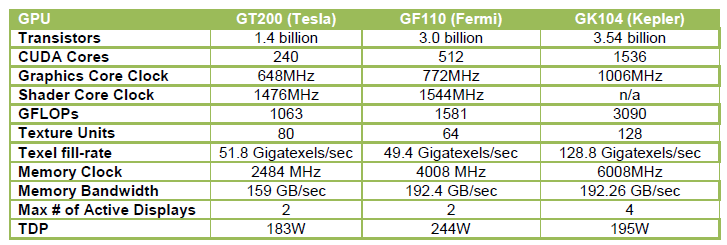
Rispetto alla precedente architettura Fermi, i numeri di Kepler sono ben più "pesanti" ma quel che vogliamo notare è il fatto che la banda di memoria sia rimasta esattamente la stessa (Kepler ha memorie più veloci ma un bus meno ampio di Fermi che aveva 6 memory controller) e che i consumi siano nettamente diminuiti, tornando ai livelli di quelli della vecchia Tesla GT200.
Visto che il blocco più importante dell'architettura Kepler è quello indicato con GPC analizziamolo più in dettaglio confrontandolo anche con quello di Fermi. Come già detto Kepler contiene 4 GPC che permettono di elaborare 32 pixels per ciclo di clock. All'interno di ogni GPC di Kepler sono presenti due SMX invece dei quattro disponibili nei GPC di Fermi ma ognuno di essi dispone di un maggior numero di unità rispetto al passato.

Blocco Streaming Multiprocessor di Kepler
 Blocco GPC di Fermi
Blocco GPC di Fermi
I singoli blocchi presenti all'interno di ogni SMX non sono cambiati molto rispetto a quelli di Fermi tranne alcune eccezioni. I CUDA cores continuano a gestire le operazioni di pixel, vertex e geometry shading oltre ai calcoli relativi alla fisica ed al GPU computing, le texture unit continuano ad occuparsi dei filtri e le unità LD/ST di caricare e salvare i dati in memoria. Esistono, come in Fermi, delle SFU o Special Function Units che si occupano principalmente di calcoli speciali come quelli trascendentali o di interpolazione.
 Fermi vs. Kepler
Fermi vs. Kepler
Anche il blocco PolyMorph Engine, che raggiunge la versione 2.0, è ancora presente seppure con le dovute ottimizzazioni. Questa unità è responsabile in particolare della gestione delle operazioni di tessellation ed è stata migliorata in modo da cercare di evitare penalizzazioni pesanti sulle performance di rendering a causa di un fattore di tessellation elevato.

L'idea di NVIDIA è quella di supportare gli sviluppatori anche per il prossimo futuro quando e se essi decideranno di migliorare la qualità della tessellation utilizzando un maggior numero di triangoli. Non deve ingannare il fatto che rispetto a Fermi il numero di PolyMorph Engine è dimezzato (8 contro 16): le unità di Kepler garantiscono prestazioni per clock circa doppie e queste, unite alla frequenza di funzionamento del chip ben più elevata, fa si che complessivamente si possano ottenere prestazioni del 30% circa superiori.
NVIDIA afferma che le ottimizzazioni apportate sia sulla composizione del blocco SMX stesso che sulle singole unità, permette a Kepler di ottenere non solo un vantaggio prestazionale rispetto a Fermi, ma anche una maggiore efficienza. Il produttore ha poi sapientemente combinato un maggior numero di unità con frequenze più elevate per far si che, dove il throughput per-clock non risulti superiore, ci pensa la frequenza di funzionamento.
In realtà quanto detto non è del tutto esatto: se la frequenza del chip è stata incrementata portandola oltre la soglia del GHz (forse anche in risposta ai proclami di AMD di poche settimane fa), NVIDIA ha abbandonato l'idea di avere una doppia frequenza (una per il chip ed una per gli shader).

Una delle prime differenze che saltano all'occhio guardando l'architettura Kepler per le GeForce GTX 680 è che il numero totale di SMX è pari ad 8 invece che a 16 come succede per le GeForce GTX 580. La motivazione di questa scelta sta nel cercare di migliorare l'efficienza del chip creando un minor numero di blocchi che racchiudano più unità e riescano a fornire prestazioni superiori.
Per garantire il flusso di dati necessario alle unità di esecuzione del blocco SMX vengono utilizzati quattro warp scheduler ognuno capace di fornire due istruzioni per ciclo di clock, esattamente come accadeva con Fermi. In Kepler, però, queste unità sono state riprogettate per migliorarne l'efficienza e, a fronte degli stessi blocchi hardware per gestire le stesse funzioni, è stata ridotta la complessità di quegli stadi che tutto sommato non apportano un vantaggio reale ma - di contro - consumano molto.
Seguendo gli stessi principi è stato migliorato il singolo processor execution core sul quale sono state apportate modifiche in ottica di riduzione delle connessioni e massimizzazione dell'efficienza del clock gating.
Questo è esattamente quanto dicevamo in precedenza circa l'eliminazione dello shader clock, feature introdotta nell'architettura Tesla come parametro di ottimizzazione dell'area del chip. In pratica, visto che la tecnologia di produzione di quel tempo non permetteva di integrare un maggior numero di transistor in un chip, per ottenere il throughput che NVIDIA si era prefissata, la frequenza di funzionamento di tali unità è stata raddoppiata rispetto alla frequenza del chip.

Basta un semplice calcolo per capire che questa scelta porta a consumi 4 volte superiori per quelle unità. Un clock doppio implica anche il raddoppio degli stadi di pipeline, ognuno funzionanti al doppio della frequenza nominale, il che porta complessivamente ad assorbimenti 2x2 volte superiori. Anche se Kepler dispone di un numero di unità doppie ciò comporta consumi "solo" doppi, recuperando un fattore due rispetto a Fermi. Perciò in questo caso, anche grazie al più avanzato processo produttivo, NVIDIA ha scelto un'ottimizzazione in termini di potenza invece che in termini di area.