Quando si crea e disegna una uArch si cerca di bilanciare ogni componente della futura CPU per far sì che ci sia il minor numero di colli di bottiglia, così che tutto risulti equilibrato. Ad esempio, è inutile avere delle unità di esecuzione velocissime, se l’accesso alla Cache è lento. Ugualmente, è inutile progettare una CPU studiata per rendere al massimo con frequenze altissime, se il silicio non lo permette. Gli ingegneri, quindi, devono realizzare una CPU equilibrata, ma per far questo devono sottostare a diversi paletti, che porteranno poi al prodotto con il miglior rapporto costo/prestazioni/consumi.
La già citata Cache è tra i principali responsabili delle prestazioni di una CPU (Ad esempio, la lentissima Cache L2 ed L3 delle CPU BD di AMD è ancora oggi una zavorra pesantissima!). Si tratta di un quantitativo di memoria adibito a conservare quei dati che, secondo le Branch Prediction (Le unità che sono preposte ad anticipare le richieste delle unità di calcolo), dovranno essere utilizzati nel brevissimo periodo. La Cache si suddivide in vari stadi, ed oggi troviamo principalmente la L1, la L2 e la L3. La L1, oltre ad essere la più “piccola”, è anche quella più veloce. Qualora i dati richiesti non fossero presenti qui (Cache Miss), si andrebbe a pescare nella L2, più grande ma anche più lenta. Nel caso non fossero presenti neppure qui, ecco che entra in gioco la L3, ancora più ampia ed altrettanto più lenta. Nel caso più sfortunato, si dovrà accedere alla RAM di sistema, molto più lenta!
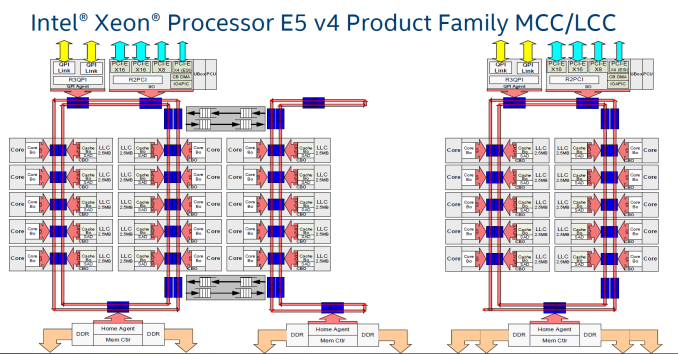
A sinistra potete osservare lo schema di distribuzione dei core in un Die MCC, come quello dell'i7-6850X. Il Ringbus (In grigio) collega le Cache L2 e L3 dei due "moduli" da 10 e 5 core.
Nel caso voleste approfondire questo argomento, su come lavora la Cache e sulla sua evoluzione, qui di seguito vi proponiamo un elenco di articoli e studi:
- ExtremeTech: How L1 and L2 CPU caches work, and why they’re an essential part of modern chips
- Hardware Secrets: How The Cache Memory Works
- Alberto Marchetti Spaccamela, Professore Ordinario, UniRoma: Cache e Gerarchia di Memoria
Quindi, non volendo essere questo un articolo didattico, andremo semplicemente ad analizzare le prestazioni dei vari livelli di Cache di Broadwell-E/EP, e di come queste cambino con l'HyperThreading attivato e disattivato.
| CPU | i7-3960X | i7-6950X | i7-6700K |
| Core | 6 | 10 | 4 |
| Frequenza/Turbo | 3.0/3.3 GHz | 3.0/3.5 GHz | 4.0/4.2 GHz |
| Cache L1 | 6 x 32KB 8-way set associative instruction cache 6 x 32KB 8-way set associative data cache |
10 x 32KB 8-way set associative instruction cache 10 x 32KB 8-way set associative data cache |
4 x 32KB 8-way set associative instruction cache 4 x 32KB 8-way set associative data cache |
| Cache L2 | 6 x 256KB 8-way set associative cache | 10 x 256KB 8-way set associative cache | 4 x 256KB 4-way set associative cache |
| Cache L3 | 15MB 20-way set associative shared cache | 25MB 20-way set associative shared cache | 8MB 16-way set associative shared cache |
Come è possibile osservare dagli screen qui in basso, le Cache L2 e L3 dell'i7-6950X sono decisamente più lente di quelle presenti nella CPU i7-6700K (Skylake-S), anche di oltre il 28%, in quanto a Latenze. Questo è determinato dal minore numero di Way di Skylake: questa soluzione velocizza l'accesso ai dati, ma potrebbe portare con più probabilità ad un Cache Miss. Questo perché in ambito Enterprise è preferibile avere una Cache un poco più lenta, ma in grado di poter mappare più porzioni di memoria, come in Broadwell-E/EP (O come AMD decise di fare con la uArch Bulldozer).
Inoltre, l'aver dovuto utilizzare - probabilmente - una sorta di CacheBus per collegare le Cache L2 e L3 di tutti i core (Essendo distribuiti in un disegno 10+5), alza drasticamente le latenze in Broadwell-E. Normalmente serve un singolo ciclo per passare dalla Cache L1 alla Cache L2, o dalla L2 alla L3, ma il particolare disegno dei Die MCC di Broadwell-EP può portare queste latenze fino a 12 cicli, con una media di 6 cicli. Essendo il benchmark di AIDA64 molto intensivo, ogni singolo core deve pescare nella Cache di tutti gli altri core, e questo spiega le latenze altissime delle Cache L2 e L3. D'altra parte le grandi dimensioni della Cache L3, unitamente alle numerose Way, portano ad un'elevatissima Bandwidth (Va comunque detto che anche le altre CPU Broadwell-E sono caratterizzate da Cache L2 ed L3 particolarmente lente).
Va notato, in ultimo, come la presenza dell'HyperThreading (Essendo uno Scheduler Hardware) migliori notevolmente le prestazioni, soprattutto nelle operazioni di Lettura.
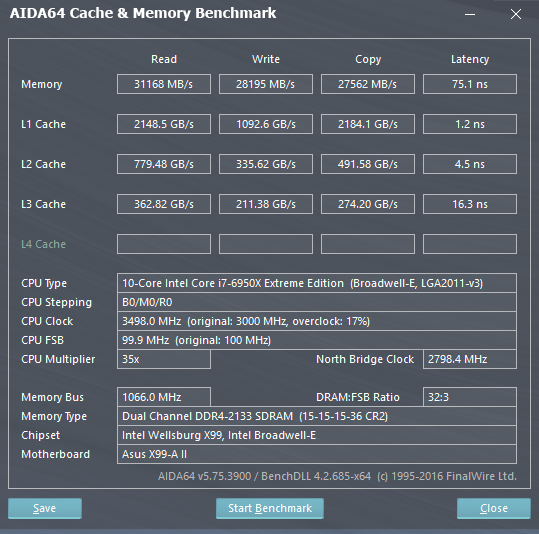
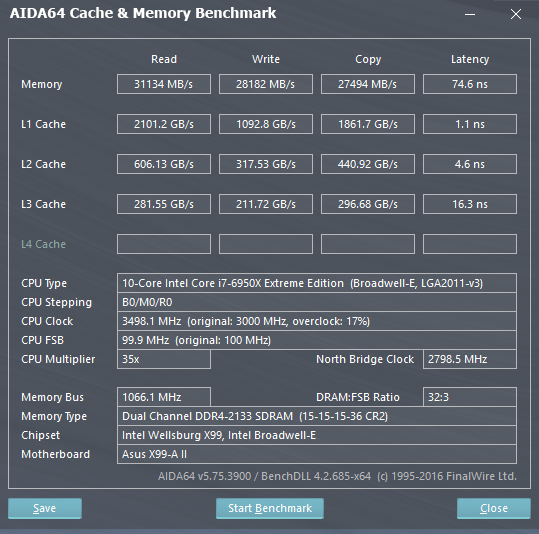
Cache & Memory Benchmark di AIDA64 con l'i7-6950X, a destra con HT disabilitato
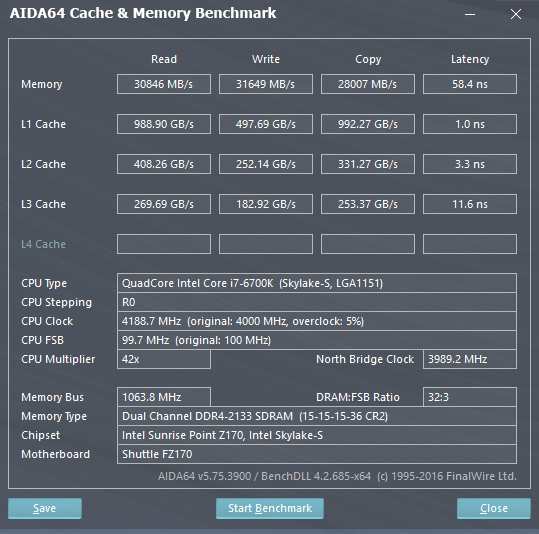
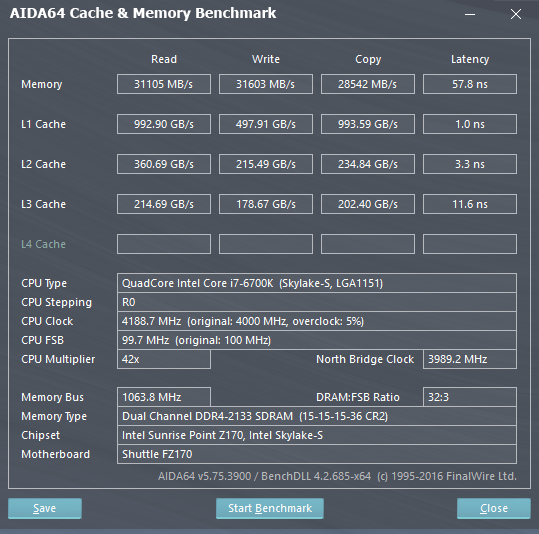
Cache & Memory Benchmark di AIDA64 con l'i7-6700K, a destra con HT disabilitato
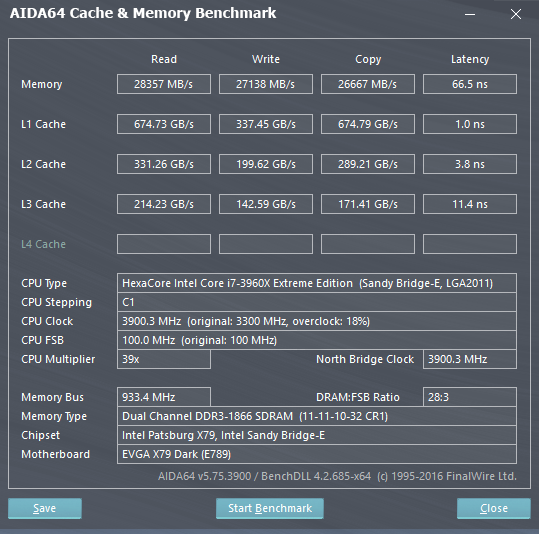
Cache & Memory Benchmark di AIDA64 con l'i7-3960X, HT abilitato