Intel, con Skylake-SP, ha deciso di dare una notevole svecchiata alle proprie uArch che ci portiamo dietro da Nehalem, ed in un certo senso ha creato diversi grattacapi ai propri utenti, al pari di quanto fatto da AMD con Ryzen. Diciamo questo non perché le due uArch (Zen e Skylake-SP) siano mediocri, anzi!, quanto perché impongono all’utente di tenere conto di ulteriori variabili, soprattutto quando si devono impostare le RAM (Frequenze e Timing). In un certo senso, sembra di essere tornati ai tempi dell’introduzione degli Athlon64 e dell’HyperTransport! Un mondo tutto nuovo rispetto ai classici Front Side Bus cui eravamo abituati!
Prima di analizzare i test effettuati, vediamo dunque di capire in cosa consistono queste diversità rispetto alle uArch Intel precedenti.
Pagina ufficiale del Core i7-7800X.
Parlando delle feature standard, cui siamo ormai abituati, l'i7-7800X integra la tecnologia Turbo Boost 2.0, la quale permette di spingere il clock dei core dai 3.5 GHz di base fino a 4 GHz. Su questo modello di base non è abilitata la tecnologia Turbo Boost 3.0, ma dal nostro punto di vista non è un problema. Essendo una tecnologia ibrida software-hardware potrebbe creare problemi (Noi siamo per l'hardware duro e crudo!). Le linee PCI-E 3.0 sono solo 28, rispetto alle 44 disponibili sui modelli 10 core o superiori, ma anche in questo caso è un "non problema" dal nostro punto di vista, almeno per il videogiocatore: le configurazioni multi GPU (SLI e CF) sono morte da un pezzo in quanto ad utilità pratica.
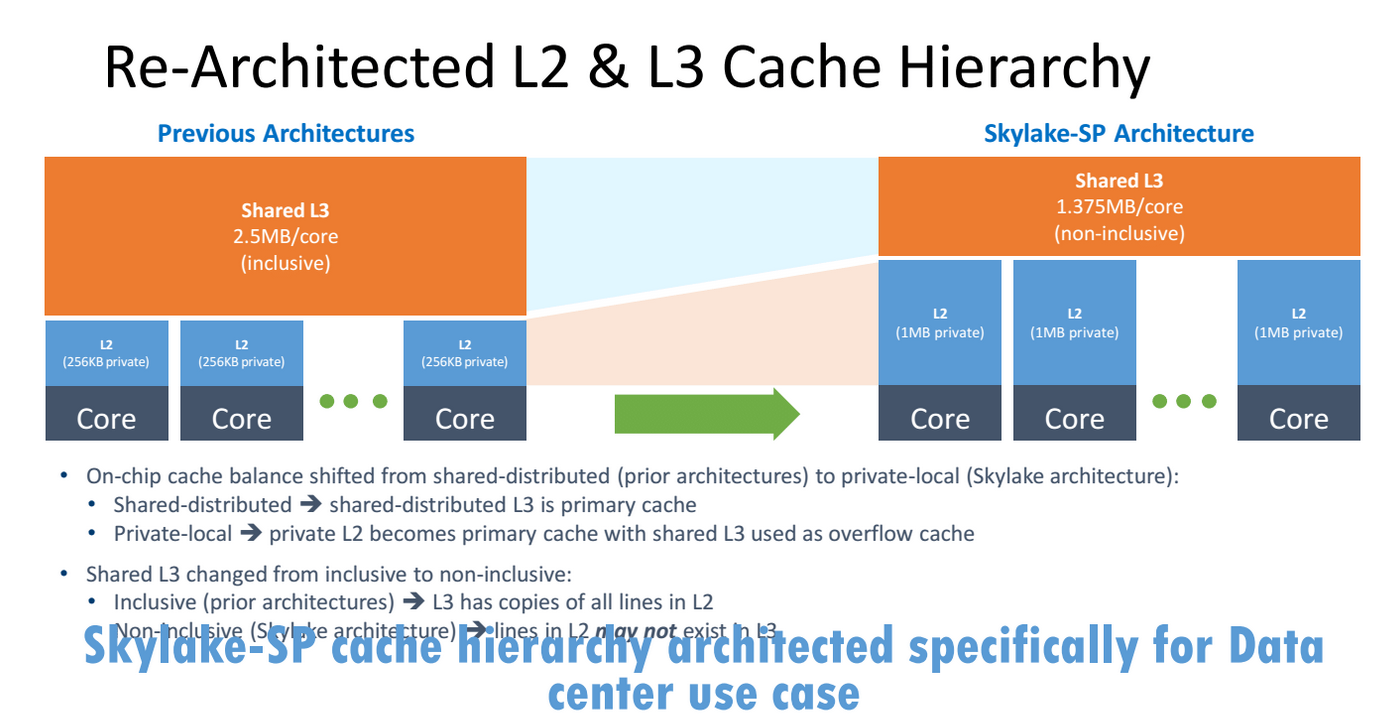
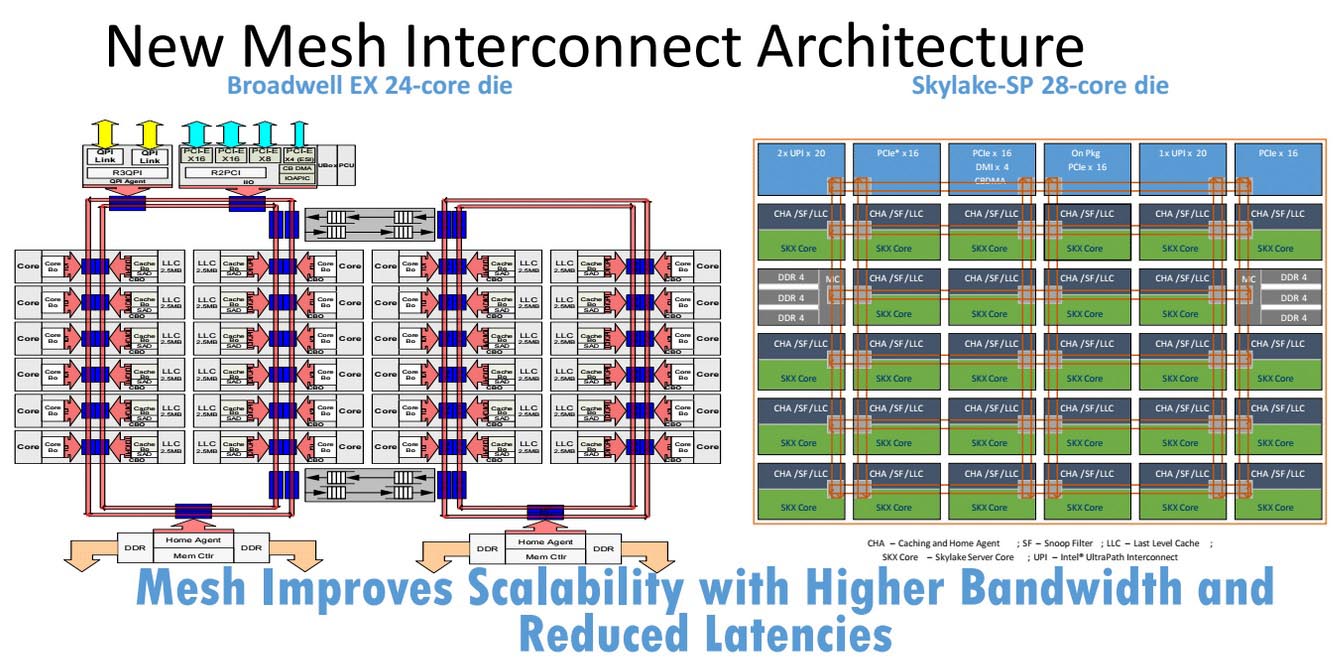
La più grande novità di Skylake-SP, invece, è sicuramente la gestione della Cache in relazione all’aumento del numero di core integrati on-Die. Il classico RingBus cui eravamo abituati è stato sostituito dalla tecnologia Mesh Interconnect Architecture. Come avevamo già avuto modo di constatare nella recensione dell’i7-6950X, con il RingBus, all’aumentare del numero dei core, si aumentava notevolmente anche la latenza della Cache, soprattutto quella di terzo livello.
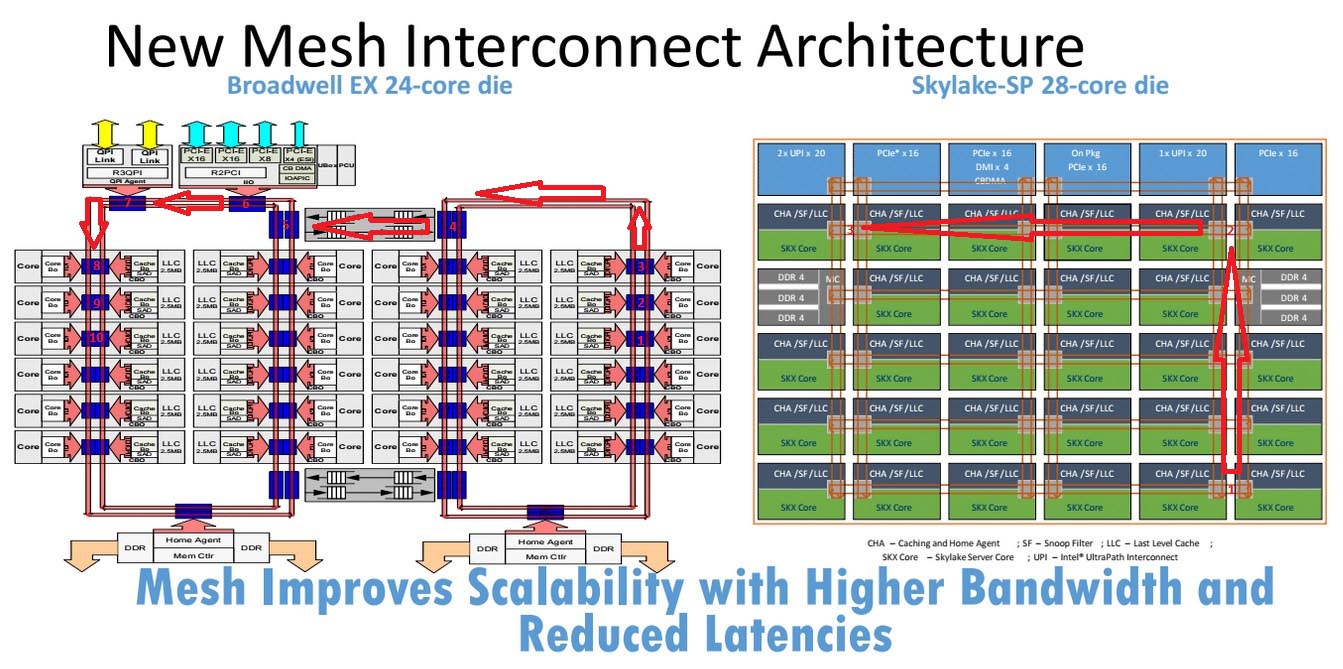
Questo accadeva perché, quando al processore si richiedeva di sfruttare un dato posto nella Cache di un altro blocco di core, si poteva arrivare a dover subire uno stop lungo fino a 12 cicli, con una media di 6 cicli. Grazie al design Mesh Interconnect Architecture, invece, la latenza può essere ridotta ad appena 2 cicli. Per esemplificare ho cercato di simulare la richiesta di un dato (Slide a destra), da parte di un core posto all’estremità dell’altro. Nel primo caso (RingBus) sono stati necessari 9 cicli, nel secondo (Mesh Interconnect) appena 2. Possiamo prendere ad esempio “visibile” della Mesh Interconnect Architecture il modo di lavorare dei più recenti distributori di snack installati nelle stazioni e negli aeroporti, i quali lavorano sui due assi X e Y.
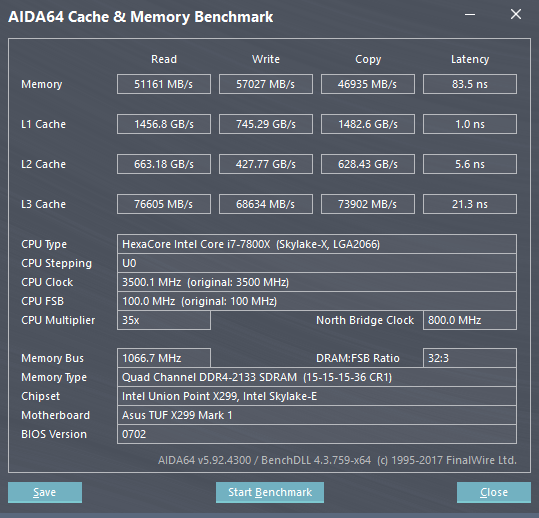
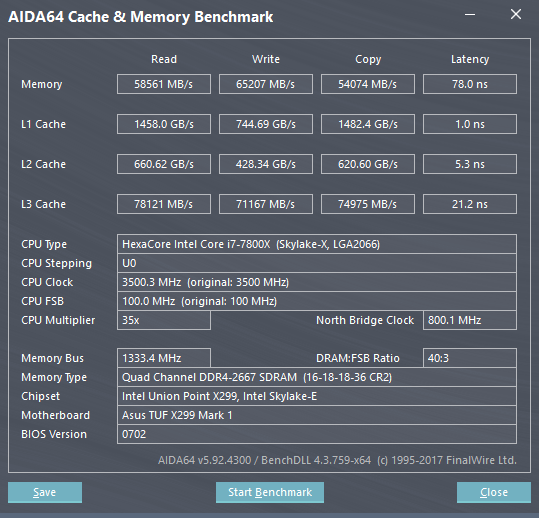
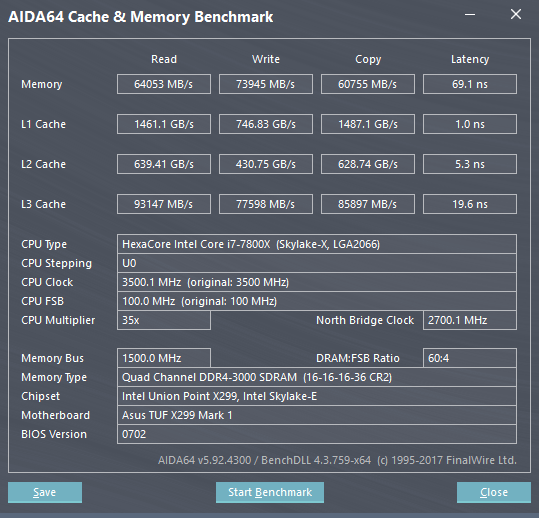
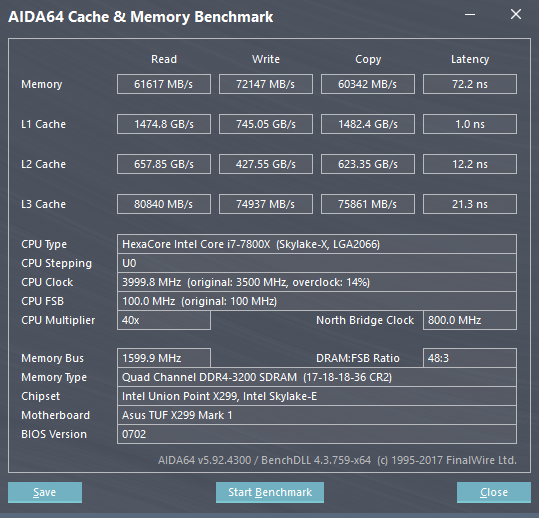
Grazie a questa novità si rende meno dipendenti i core da una Cache L3 di notevoli dimensioni, in quanto la velocità di fruizione risulta più rapida. Sempre per questo motivo gli ingegneri Intel hanno deciso di diminuire proprio le dimensioni della Cache L3, in favore della L2, e di renderla anche non-inclusiva, al fine di semplificarne il disegno. Se da un lato questo ha permesso di poter contare su di una Cache L2 più veloce e più ampia, dall’altro ha reso la Cache L3 dipendente dalla velocità della memoria DDR4, in quanto la memoria RAM per leggere i dati nella Cache L3 deve prima passare dalla Cache L2. Una più veloce memoria RAM implica quindi un più veloce accesso alla Cache L3, in quanto si velocizza lo scambio dei dati (Vedere slide qui in basso). Al contrario, la Cache L2 continua ad essere non dipendente dalla velocità della RAM.
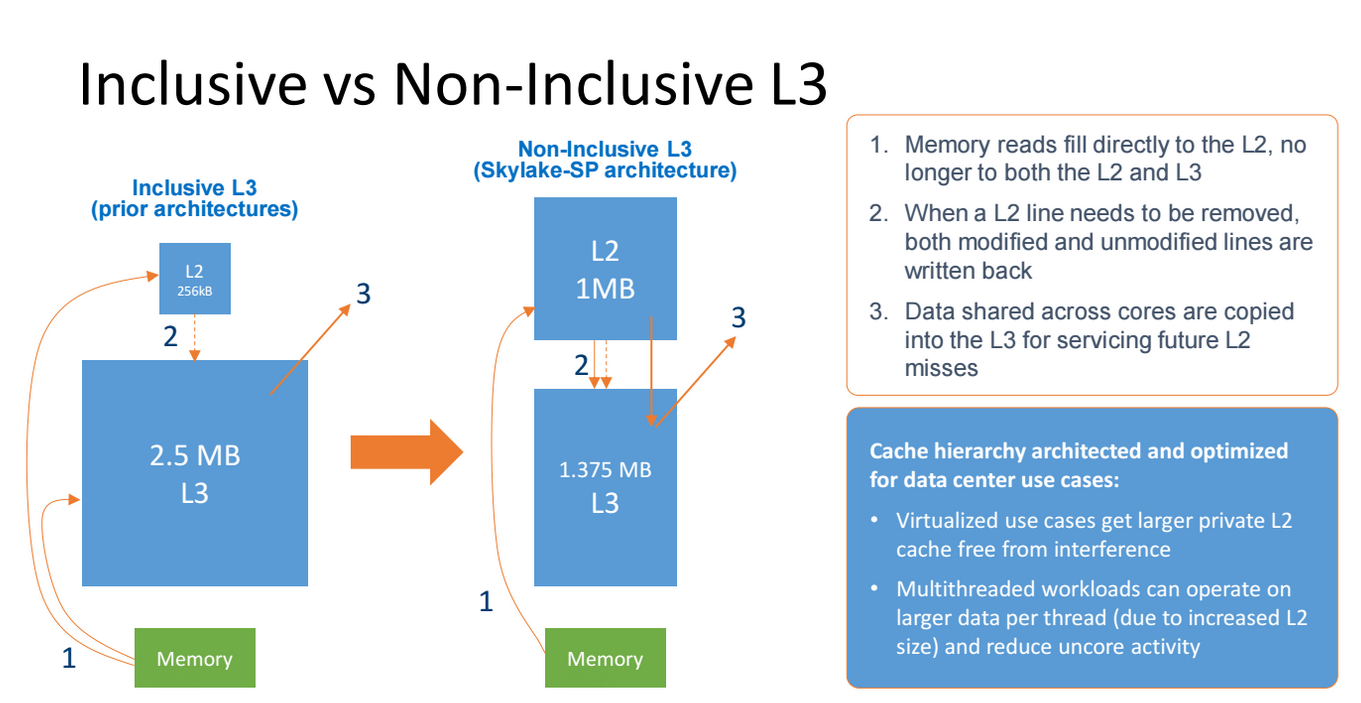
Questo lo si può notare dai test effettuati con AIDA64. Ma non si nota solo questo. Come già accaduto per la tecnologia CCX di AMD integrata nelle CPU Ryzen, anche la Mesh Interconnect Architecture risulta alquanto complicata da gestire, in quanto la propria frequenza viene calcolata utilizzando la frequenza delle DDR4 e la frequenza della CPU. Utilizzando le RAM a 3000 MHz otteniamo quindi un maggiore clock del BUS di comunicazione (2700MHz), che si traduce in una Bandwidth più elevata ed in una latenza minore, tanto per le RAM quanto per la Cache L3. Una velocità delle RAM più elevata, strano a dirsi, non è quindi per forza sinonimo di maggiori prestazioni.
A conferma di quanto da noi osservato, c'è questa discussione sul Forum ROG di Asus, in cui si spiega come overclockare le RAM con la piattaforma X299. In OP si mostra come la latenza delle DDR4 a 4133MHz sia di 71,9 ns, mentre con le RAM a 2666 Mhz questa sia pari a 78,8 ns (In linea con i nostri test, quindi). L'utente YC2CHUR fa però notare che con le RAM settate a 4000 MHz ha potuto raggiungere la latenza di 49,7 ns. A questo punto è interessante osservare il valore relativo al NorthBridge Clock del suo screen, pari a 3200MHz (Nel nostro, con le RAM settate a 3000MHz, la medesima voce fa segnare 2700MHz). Alla luce di ciò, sarebbe auspicabile testare la CPU con RAM che possano raggiungere e superare i 4 GHz, ma per il momento, sfortunatamente, ne siamo sprovvisti.
Va inoltre considerato che, al pari di quanto accaduto con Ryzen, anche con le CPU Skylake-X bisognerà "ritarare" i software (Videogiochi compresi) a causa di questo cambio di design, invero non proprio leggero. Ironicamente, Zen risulta più simile ad Haswell di quanto non lo sia Skylake-SP! Nel prossimo futuro, quindi, dovremmo aspettarci diverse patch, tanto per i software tradizionali quanto per i videogiochi, al fine di sfruttare appieno queste nuove CPU di Intel, studiate prima di tutto per il mercato Enterprise, e prestate al mercato Consumer. Mai come oggi, nei nostri PC girano uArch studiate per ben altri ambiti (Zen compreso)!