Quella che AMD definisce la "Quarta Era" delle proprie GPU si apre nel segno della nuova architettura GCN.
La prima Era (1998-2001) è stata caratterizzata dall'engine T&L di tipo fixed function, la seconda (2002-2006) dagli shaders semplici programmabili, la terza (2007-2011) dall'architettura a shaders unificati con ALU di tipo VLIW. Con Cayman, evoluzione finale della terza Era, AMD ha sperimentato le ALU simmetriche a quattro vie e inserito novità sul fronte dell'elaborazione geometrica e general-purpose.
L'architettura GCN riesce finalmente a mettere sullo stesso piano grafica 3D e GPU Computing, portando, almeno sulla carta, un sensibile incremento prestazionale in entrambi i settori tale da permettere alla casa di Sunnyvale di proseguire con il progetto di un ecosistema GPU + CPU sempre più forte che culminerà con il dopo Trinity in una serie di APU dove l'integrazione tra le due unità sarà totale e indistinguibile sia sul profilo hardware che software.
Alla base dell'architettura GCN troviamo la cosiddetta Compute Unit (CU): un singolo blocco composto da 4 Vector Units (SIMDs), ciascuna con 16 stream processors integrati, da 4 Texture Units (TMUs), da una Scalar Unit con i propri registri e da una cache L1 R/W da 16KB. Le 4 SIMDs sono pilotate da uno Scheduler affiancato da una memoria local data share da 64KB.
Rispetto alle precedenti architetture VLIW5 e VLIW4, GCN consente di raggiungere un elevato parallelismo d'elaborazione senza dover utilizzare compilatori troppo complessi e senza incappare in possibili "conflitti" sul flusso dati. Questa soluzione ha richiesto un notevole potenziamento di tutto il sistema di caching. Oltre alla cache L1, raddoppiata rispetto a Cayman, in Tahiti ogni quartetto di CU ha accesso ad una memoria da 16 KB per le istruzioni e da 32 KB per i dati. La cache L2 R/W è "partizionata" in 12 blocchi da 64KB e la comunicazione tra tutte le CU è affidata ad un Global Data Share.
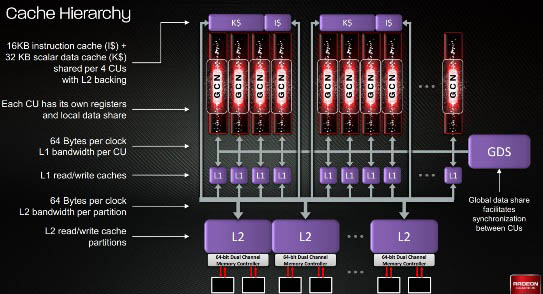
GCN: Gerarchia delle cache
Sotto forma di diagramma a blocchi Tahiti ci viene presentato in questo modo:
 GCN: architettura della derivazione Tahiti
GCN: architettura della derivazione Tahiti
Sono presenti 32 CU suddivise in due banchi da 16, per un totale di 2048 Stream Processors, con 128 TMUs, 8 Render Bach-ends (32 ROPs) e con un memory controller di tipo GDDR5 composto da 6 unità 2CH da 64-bit ciascuna (per un'interfaccia complessiva a 384-bit).

GCN: motore geometrico
Il front-end è di chiara derivazione Cayman. Troviamo due distinti Geometry Engine inizializzati da un singolo Command Processor. All'interno dei due Geometry Engine è presente un nuovo Tesselator, definito di nona generazione. Tahiti, pur implementato un approccio ai calcoli geometrici simile a Cayman, risulta più performante grazie al maggior quantitativo di cache L2 e a varie ottimizzazioni sull'off-chip buffering e sul Vertex Assembler. In particolare nelle operazioni di hard-tessellation il nuovo chip distacca sensibilmente quello della generazione precedente.
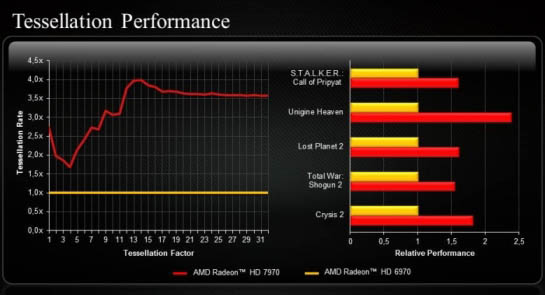
Prestazioni con del tesselator
Anche il numero di ROPs è invariato rispetto a Cayman, con un'organizzazione a 8 gruppi da 4, ma ora queste possono lavorare in maniera più veloce ed essere sfruttate al meglio grazie alla maggiore banda passante verso le memorie, messa a disposizione dai due moduli 2CH aggiuntivi.

GCN: ROPs
Passando alla parte terminale notiamo che la cache L2, condivisa tra le CU, è stata complessivamente raddoppiata (768KB) rispetto a Cayman ed ora scala in maniera indipendente dalle ROPs e dal memory controller, con quest'ultimo che, come abbiamo già detto, ha un'ampiezza complessiva di 384-bit, ottenuti con 12 chip di VRAM GDDR5 a doppia densità.

Cache L2 e memory controller