Come abbiamo anticipato, Zen3 ha portato con sé un miglioramento medio del 19% dell'IPC rispetto a Zen2, un numero GIGANTESCO per chi conosce l'ambito. A questo punto sorge spontanea una domanda: come è riuscita AMD a raggiungere un tale risultato?
Per realizzare Zen AMD, al fine di velocizzarne lo sviluppo, ha conservato diverse soluzioni ingegneristiche utilizzate dall'uArch Bulldozer, ad esempio l'unità di calcolo Floating Point e la Branch Prediction Unit, dall'uArch Star, il design della Cache, e dall'uArch Jaguar, l'Hashed Perceptron System.
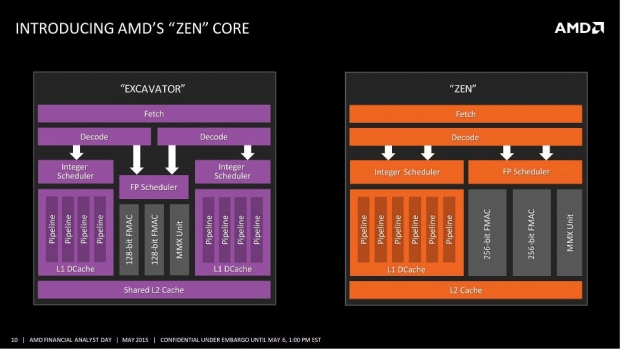
AMD, constatato che Intel non avrebbe avuto nulla da immettere sul mercato nel breve periodo, dopo Zen decise di commercializzare un piccolo aggiornamento, Zen+, così da avere tutto il tempo per completare il primo major uplift, Zen 2. Quest'ultima uArch ha migliorato notevolmente Zen 1: una nuova Branch Prediction Unit, un nuovo design della Cache, una nuova Floating Point Unit, ed altro. Possiamo notare, in questo articolo, quanto questi miglioramenti abbiano influito:
Con Zen3 AMD mette nuovamente mano ad alcune sezioni essenziali dell'uArch, ad iniziare dalle unità Integer, le quali finalmente abbandonano un design che ci portiamo dietro da Excavator. Da qui gli ottimi risultati che possiamo osservare nei videogiochi. Evidentemente AMD, con Zen 2, aveva dato priorità ai software professionali ed enterprise, migliorando le unità FP, mentre ora è giunto finalmente il momento di suonare la carica anche in campo ludico. Sempre in questo ambito, AMD ha ridisegnato in parte anche le unità FP, al fine di migliorare le latenze.

Sempre per migliorare le prestazioni, soprattutto quando ci sono notevoli salti da un core all'altro (tipico dei videogame), AMD ha deciso di unificare la Cache L3, passando da due blocchi da 16MB ad un singolo blocco da 32MB. Questo permette a tutti i core di attingere alle medesime informazioni, senza che si perda tempo per copiare le informazioni in un altro blocco, cosa che porta via molto tempo.

In ultimo AMD, nonostante abbia conservato il medesimo I/O Die, il quale integra il Memory Controller DDR4, è riuscita a migliorare notevolmente sia la Bandwidth sia le latenze. Questo significa che AMD è riuscita a rimuovere una serie di colli di bottiglia presenti nel CCX, probabilmente dovuti alla gestione della Cache che, come abbiamo visto, ha subito un notevole lifting. Ora siamo arrivati quasi ai livelli del Memory Controller delle CPU Intel.

Qui in basso, grazie al lavoro di Fritzchens Fritz, possiamo osservare il layout del CCX. Confrontando questa immagine con quella di Zen2, possiamo notare varie differenze: la Cache L3 ha subito numerosi cambiamenti, così come sono cambiati la L1 Instruction Cache e il Branch target predictor. In ultimo, i core Zen3 risultano "più tozzi" rispetto ai core Zen2.
