Alla Stanford University, dislocata al centro della Silicon Valley, IBM ha sganciato la propria “bomba” dedicata al mercato server, l'architettura Power 8. Con questa architettura Big Blue spera di poter sopravvivere nel mercato server, e soprattutto spera di poter ripagarsi le proprie fonderie, attraverso una roadmap aggressiva e alla creazione di un'ampia alleanza: “IBM is skipping a shrink from the current 32 nanometer processes used to etch its chips to a 28 nanometer process and going right straight to 22 nanometers. This is a pretty big jump--the same that Intel has made with its Xeon processors--and that gives Big Blue lots of options” ha affermato Timothy Prickett Morgan, di ITJungle.

Il processore reference basato su questa architettura si rivela un mostro a tutti gli effetti, sia dal punto di vista prestazionale, sia dal punto di vista tecnico. Parlando di meri numeri, i core (a 16 stadi) salgono a 12, rispetto agli 8 del Power7+, ed ogni core adesso può gestire fino ad 8 thread, rispetto ai 4 del predecessore, per un totale di 96 thread simultanei con un'unica CPU. E' comunque in cantiere una versione a 16 core Power 8, la quale sarà disponibile con l'avvio della produzione a 22nm.
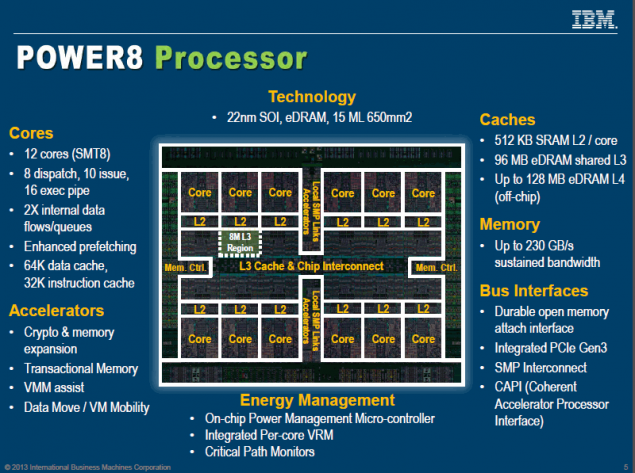



Anche la cache subisce una cospicua evoluzione. Si passa dai 10MB di cache L3 per core del Power7+, ai 96MB di cache eDram L3 shared on-die e 128MB di cache L4 eDram off-die (la stessa soluzione applicata da Intel per la memoria eDram dedicata all'iGPU Iris Pro). La Cache L1 è pari a 512KB per core.
Altre feature interessanti dell'architettura Power 8 sono la presenza del controller PCI-E 3.0 integrato (non si conoscono le linee totali, ma dovrebbero essere almeno doppie rispetto a quelle di Haswell-EX), una bandwidth della memoria di ben 230GB/s, e il VRM integrato, al pari delle CPU Haswell. Di questo VRM abbiamo parlato alcuni mesi fa, ed è disponibile sul mercato, previo pagamento della licenza per utilizzarlo.
Feature particolarmente interessante, e che ho lasciato per ultima, è la Coherently Allocated Processor Interface (CAPI), in grado di diminuire la latenza nello scambio di dati tra CPU, memoria di sistema e Co-Processori esterni (come le GPGPU di nVidia ed Intel), by-passando il collo di bottiglia principale: i driver. Il tutto, infatti, dovrebbe avvenire via hardware, velocizzando di molto le operazioni.
Questa meraviglia ingegneristica, secondo le prime supposizioni, dovrebbe avere una superficie di 650mm2 @22nm. IBM cercherà di imporre questa archiettura, almeno inzialmente, avviando una stretta collaborazione con Lenovo ed il governo della Repubblica Popolare Cinese. Essendo un'architettura aperta, e ad alte prestazioni, sarebbe perfetta per il grande stato asiatico, volenteroso nello staccarsi dalle aziende come nVidia ed Intel.