L’uArch “Zen+” a prima vista non sembra discostarsi troppo dalla prima iterazione, eppure nei suoi meandri possiamo osservare come le differenze siano notevoli. Applicando una strategia simile a quella applicata da Intel nel primo decennio degli anni 2000, AMD ha deciso di portare avanti un rinnovamento su due fronti con Zen+: si è migliorata l’uArch, sfruttando i punti di forza del Processo Produttivo di GlobalFoundries.
Moltissimi giornalisti ed appassionati hanno sempre considerato la vendita delle proprie FAB un grave errore da parte di AMD, in quanto si sarebbe più potuto lavorare su un progetto organico come avrebbe continuato a fare Intel: creare un Processo Produttivo tagliato su misura per l’uArch di riferimento.
A Londra, le cose che ci hanno raccontato vanno della direzione diametralmente opposta, o quasi. È vero che AMD non può decidere la roadmap di GlobalFoundries, ma comunque quest’ultima sta cercando di venire incontro alle esigenze della casa in rosso. Allo stesso tempo, conoscendo con largo anticipo i progetti sui 12nm FinFET, AMD ha potuto sviluppare un’evoluzione architetturale in grado di sfruttarne i vantaggi.



Per chiarire il discorso, è vero che i 12nm FinFET di GloFo non hanno garantito i 4,5 GHz di frequenza Turbo che in molti si aspettavano (Si è comunque arrivati ad un ragguardevole 4,35 GHz), ma ha comunque permesso ad AMD di migliorare notevolmente l’IMC DDR4 e le Cache L2 ed L3. Questo importantissimo miglioramento ha spinto l’IPC delle CPU Ryzen 2 praticamente alla pari con le CPU Intel CoffeeLake. Ora manca solo la frequenza pura, ma AMD è fiduciosa. I 7nm di TSMC e GloFo sono in arrivo per raggiungere questo obiettivo! E mentre AMD cerca di migliorare le prestazioni ST di Ryzen, c'è Intel che si è accorta che avere molti core, in un prossimo futuro, sarà essenziale. Il bello della concorrenza: basta CPU 4C/4T a 250 Euro!


Joe Macri, CTO della Divisione Client di AMD, descrive Ryzen 2
Tornando ai 12nm FinFET, Joe Macri ha parlato di “Faster transistors”. GlobalFoundries ha migliorato i 14nm FinFET, in modo che i transistor possano switchare più velocemente dagli stati attivi (ON) a quelli passivi (OFF), e che possano operare a tensioni ridotte. Tutto questo ha garantito ad AMD la possibilità di migliorare la Bandwidth e le latenze delle memorie in maniera enorme.
Altri miglioramenti all’uArch, riguardano l’aggiornamento della gestione del Turbo (XFR2), attraverso il quale non solo è possibile raggiungere frequenze più elevate, ma anche sfruttarle per una quantità maggiore di tempo, grazie ad un’elevata granularità di step.

Alcuni tra i giornalisti presenti. I primi tre a sinistra sono di nazionalità spagnola, mentre in successione possiamo citare Paolo Corsini (HWUP), Andrea Ferrario (TOMSHW) e Davide Fasola (HDBLOG)
Per farci testare di persona tutte queste novità, AMD ci ha messo a disposizione, in quel di Londra, una serie di postazioni, equipaggiate con CPU Ryzen 7 2700X abbinate ad diverse schede madri (AsRock, Asus, Gigabyte, MSI) e a diversi sistemi di raffreddamento (AiO e Aria).

Una postazione, tra quelle messe a disposizione.
Personalmente per prima cosa, appena messe le mani su una postazione libera, ho voluto testare Cinebench 15 e, saltato fuori il risultato di 1807 con frequenze default, ho sgranato gli occhi. Mica male per un semplice aggiornamento di CPU, se pensiamo che il 1700X in nostro possesso ha un punteggio di 1564!
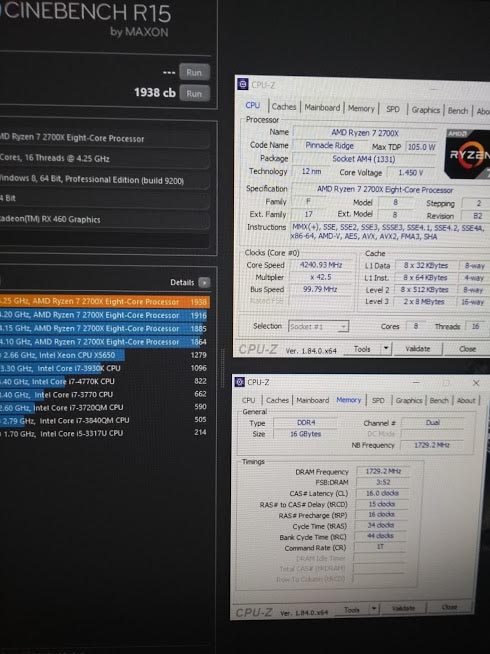
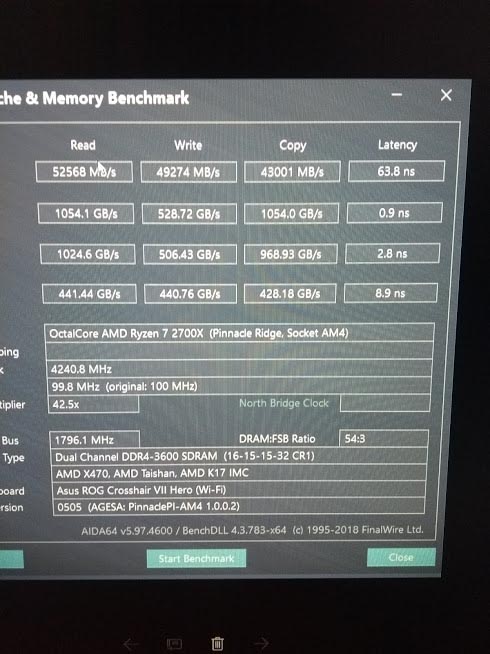
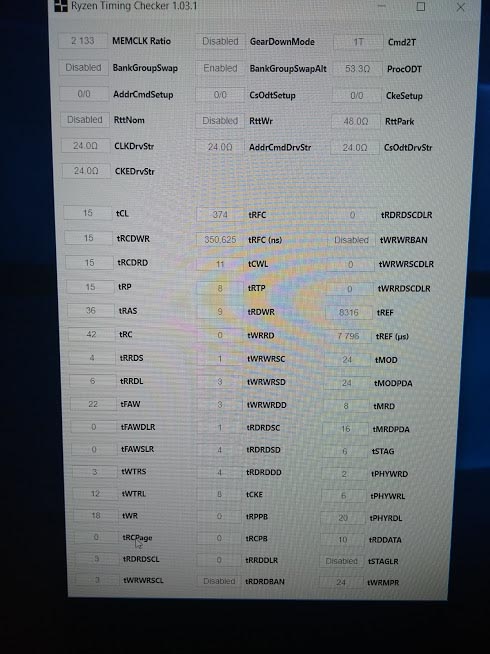
Qui le foto che ho fatto, dopo aver overclockato leggermente il Ryzen 7 2700X che avevo sottomano a Londra. Dissipato ad Aria. Non ho voluto strapazzarlo eccessivamente dal punto di vista del vCore (Mi ero fermato a 1.40v). Frequenza e prestazioni non sono male davvero, e le RAM di G.Skill (Le stesse del Kit che abbiamo ricevuto) sono riuscite a tenere ottimi timing!
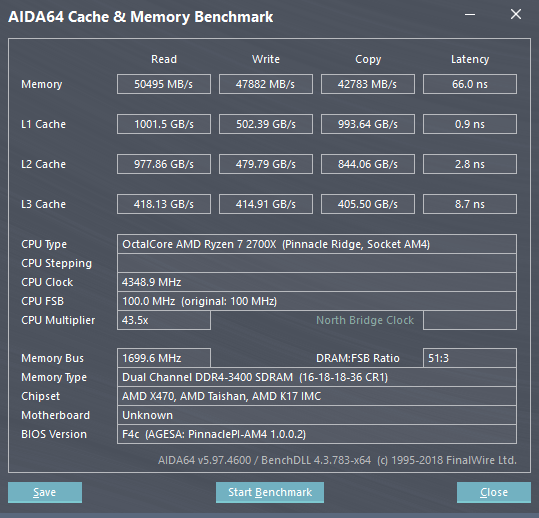
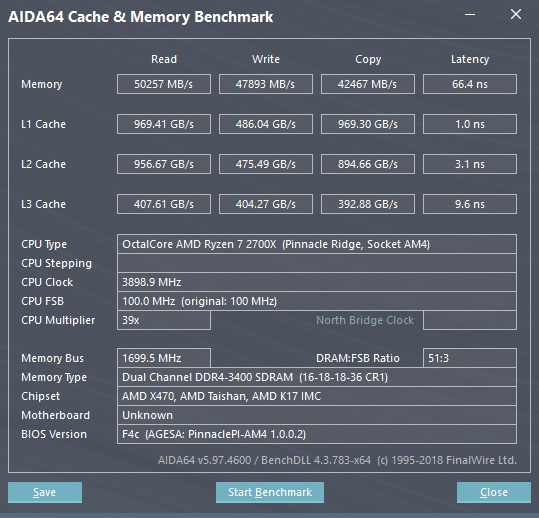
Subito, ho aperto AIDA64 per testare l’IMC e le Cache, in quanto era pacifico che questo miglioramento non potesse essere solo una questione di frequenze. Ed ecco la bomba: Bandwidth e Latenze sono migliorate tantissimo! Quello che si era detto durante la presentazione alla fine è risultato vero, niente false promesse.
Per esplicitare al meglio il miglioramento che possiamo osservare nel passaggio dal Ryzen 7 1700X al Ryzen 7 2700X (Disponibili attualmente in commercio a circa lo stesso prezzo), ecco qui alcuni benchmark comparativi eseguiti con AIDA64, alla medesima frequenza. Si tratta sicuramente un ottimo boost, tanto per i videogiocatori, quanto per gli utenti che utilizzano software professionali.
| CPU | Ryzen 7 2700X @3.9GHz | Ryzen 7 1700X @3.9 GHz |
Miglioramento % |
| Read DDR4 (MB/s) | 50257 | 48937 | +2,70% |
| Write DDR4 (MB/s) | 47893 | 48450 | -1,15% |
| Copy DDR4 (MB/s) | 42467 | 42983 | -1,20% |
| Latency DDR4 (ns) | 66,4 | 72,3 | +8,16% |
| Read Cache L1 (GB/s) | 969,67 | 868,52 | +11,65% |
| Write Cache L1 (GB/s) | 486,04 | 435,37 | +11,64% |
| Copy Cache L1 (GB/s) | 969,30 | 868,22 | +11,64% |
| Latency Cache L2 (ns) | 1,0 | 1,0 | +0% |
| Read Cache L2 (GB/s) | 956,67 | 827,09 | +15,67% |
| Write Cache L2 (GB/s) | 475,49 | 424,92 | +11,90% |
| Copy Cache L2 (GB/s) | 894,66 | 733,64 | +21,95% |
| Latency Cache L2 (ns) | 3,1 | 4,4 | +29,55% |
| Read Cache L3 (GB/s) | 407,61 | 368,18 | +10,71% |
| Write Cache L3 (GB/s) | 404,27 | 365,87 | +10,50% |
| Copy Cache L3 (GB/s) | 392,88 | 432,01 | +9,96% |
| Latency Cache L3 (ns) | 9,6 | 11,5 | +16,52% |
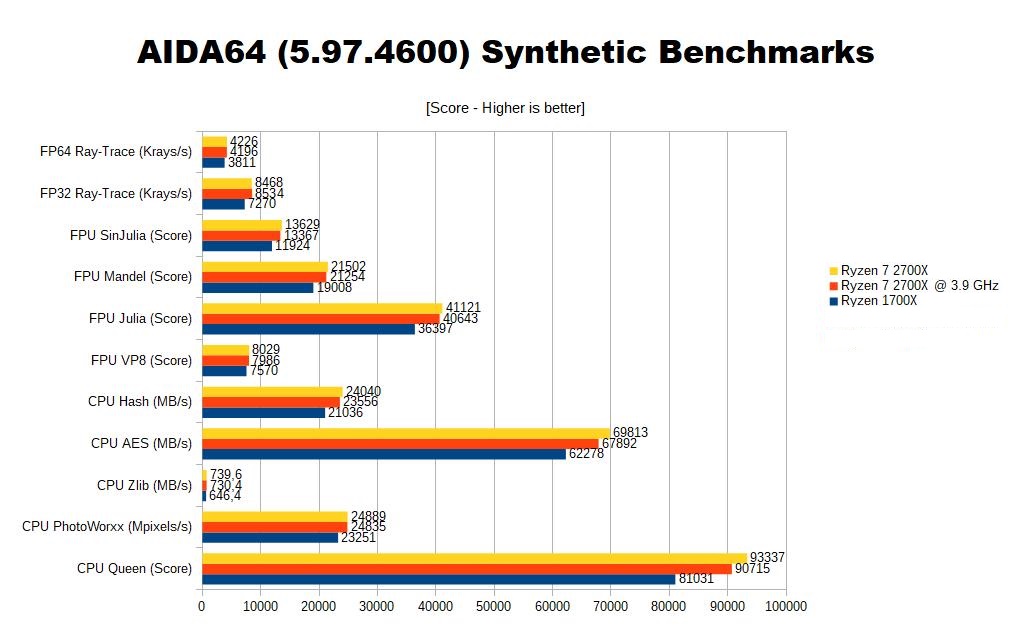
In questi benchmark effettuati con AIDA64 Engineer, possiamo notare come i test che sfruttano di più la Cache (CPU Queen, CPU AES, CPU Hash, FPU Julia) godano di un notevole boost. L'aumento di frequenza della CPU, in proporzione, ha un impatto minore.
Qui di seguito, invece, lo screen di CPUz relativo al Ryzen 7 2700X a frequenze default. Come potete osservare, le differenze rispetto al Ryzen 7 2700X settato a 3.9 GHz sono minime, segno che le prestazioni della Cache è determinata non tanto da un aumento di frequenza, quanto da un miglioramento generale del Design e del Processo Produttivo di GlobalFoundries.