Zen+ è stato poco più di un refresh dell'uArch Zen, come abbiamo avuto modo di osservare nei nostri test. AMD, in particolare, ha cercato di migliorare Bandwidth e Latenze della Cache, così da aumentare le performance in quelle applicazioni Cache Sensitive (Ad esempio i videogiochi) che vedevano eccessivamente avvantaggiate le CPU di Intel. AMD, inoltre, sfruttando il nodo 12nm FF di GlobalFoundries (Evoluzione dei 14nm FF sempre di GloFo) è riuscita ad aumentare le frequenze operative, limitando così - probabilmente - il principale punto debole della prima generazione di CPU Ryzen. Unitamente al cambio di processo produttivo, AMD ha introdotto la tecnologia XFR2, così da poter garatire un turbo boost più elevato.
Con l'uarch Zen2 AMD ha effettuato un major update nel design, in quanto le modifiche sono sostanziali ed anche molto profonde. Come avevamo riportato alla presentazione della prima generazione di Ryzen, il team dietro Zen si è trovata costretta a riciclare (affinandoli, naturalmente) un po' di "moduli" derivati da Bulldozer, Star e Jaguar: la Branch Prediction Unit di BD, il design della Cache di Star, l'Hashed Perceptron System di Jaguar, ecc.
A distanza di due anni, in tutta sicurezza, il team Zen è riuscito ad implementare una serie di novità in grado di portare notevoli miglioramenti. Prima di tutto, Zen2 offre una migliore Branch Prediction Unit (AMD ha dichiarato che è stata completamente ridisegnata), unitamente ad una Cache dal design più sofisticato. Secondo AMD, la nuova Branch Prediction Unit (BPU) garantirebbe un miglioramento del 30% nelle predizioni (Un'altra novità è l'introduzione del TAGE predictor specificatamente per la Cache L2). Tutto questo si è reso necessario per sfruttare la nuova Floating Point Unit, ora in grado di sfruttare le istruzioni AVX2 (all'Hot Chips di agosto AMD fornirà tutti i dettagli a riguardo).
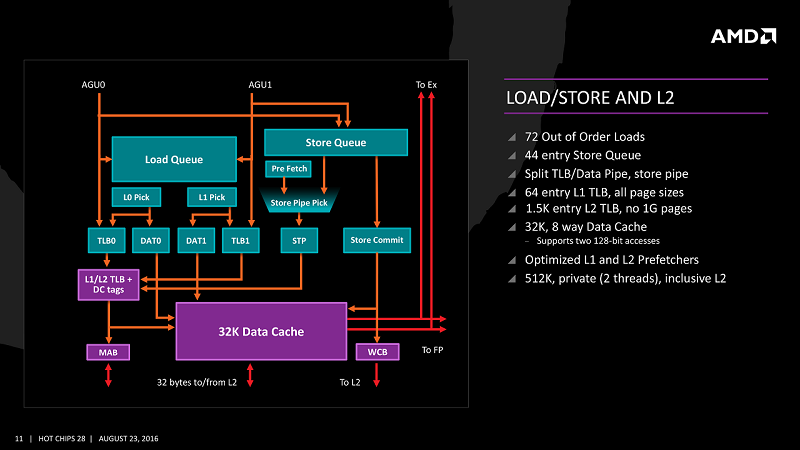
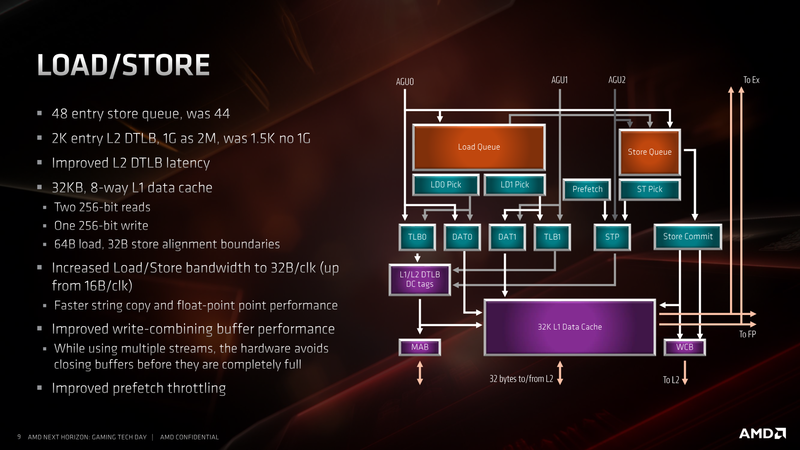
A sinistra lo schema dell'unità di Load/Store di Zen, a destra di Zen2
| uArch | Zen | Zen2 |
| Cache L1 | 8 x 64 KB 4-way set associative instruction cache 8 x 32 KB 8-way set associative data cache |
8 x 32 KB 8-way set associative instruction cache 8 x 32 KB 8-way set associative data cache |
| Cache L1 Org. | 4-way, 256 set | 8-way, 64 set |
| Cache L2 | 8 x 512 KB 8-way set associative unified cache | 8 x 512 KB 8-way set associative unified cache |
| Cache L3 | 2 x 8 MB 16-way set associative shared cache | 32 MB 16-way set associative shared cache |
Possiamo notare come lo spazio risparmiato dal dimezzamento della Cache L1-I (da 64KB a 32KB) abbia permesso ad AMD di raddoppiare la dimensione della cache micro-op (da 4-way a 8-way), favorendo una maggiore efficienza grazie anche la raddoppio della Cache L3, sempre di tipo Victim Cache (AMD utilizza questa tipologia di Cache fin dall'Athlon64): questa è utilizzata come "parcheggio" per quelle informazioni che non possono essere stockate nella Cache L2 (Nelle CPU Intel, a parte quelle con uArch Skylake-X, i dati della Cache L2 sono disponbili anche nella Cache L3. La Cache L3 è cioè di tipo "Inclusive" e vi ridondanza di informazioni).


L'introduzione di una nuova e più efficiente Branch Prediction Unit, la Cache ridisegnata, la migliorata unità di Load/Store, l'aggiunta di una terza AGU e molto altro farebbero parte di una nuova strategia da parte di AMD che lascerebbe presagire l'abbandono del progetto Fusion, secondo quanto riporta Hiroshige Goto, guru giapponese delle CPU. AMD, infatti, avrebbe intenzione di proseguire su questa strada con Zen 3 e Zen 4, studiando core sempre più "massicci" e complessi, al fine di offrire CPU potenti ed efficienti. Bulldozer (Int oriented) era stato sviluppato per essere utilizzato in combinazione con le GPU (FP oriented). Zen, al contrario, è nato per essere una CPU a tutto tondo a cui affiancare acceleratori discreti. Per il momento, quindi, addio al progetto HSA (Heterogeneous System Architecture). Zen è una risposta diretta alle uArch Core di Intel.
In ultimo, con Zen2 AMD ha introdotto tre nuove istruzioni (Alcune attese anche con Ice Lake), come anticipato in questo nostro tweet di 9 mesi fa.
About the new Zen2 instructions:
— Bits And Chips - Eng (@BitsAndChipsEng) 8 novembre 2018
CLWB (Since Skylake)
RDPID (Ready with Ice Lake)
WBNOINVD (Ready with Ice Lake)
Source: https://t.co/HRdxRdPiId
AMD is leapfrogging Intel in every field.
- CLWB permette ad un software di ripristinare i dati nella memoria non voltatile al fine di prevenire la perdita di informazioni qualora il sistema riceva un comando di alt;
- RDPID permette di prevenire il completo utilizzo di Cache e Memoria da parte di una macchina virtuale;
- WBNOINVD permette di pulire una porzione di cache istantamentamente quando un'istruzione è pronta per essere eseguita all'interno della pipeline.